Go 基础知识
文章目录
Go 简介
Go 语言起源 2007 年,并于 2009 年正式对外发布,其是谷歌公司的一个开源项目。Go 语言并不是凭空而造的,而是和 C++、Java 和 C# 一样属于 C 系。
Go 语言本身是由 C 语言开发的,而不是 Go 语言。但 Go 在 1.5 版本开始自举。
Go 编译器:gc (官方)和 gccgo。
Go 是一门编译型,具有静态类型和类 C 语言语法的语言,并且有垃圾回收(GC)机制,属于静态语言。
Go 是一门与时代相符的主流系统编程语言。
编译是将源代码翻译为更加低级的语言的过程 —— 翻译成汇编语言(例如 Go),或是翻译成其他中间语言(如 Java 和 C#)。
使用 GO 开发的开源项目:docker, k8s, grpc, etcd
Go Logo
Go 通过以下的 Logo 来展示它的速度,并以囊地鼠(Gopher)作为它的吉祥物。
为什么要创造一门编程语言
在 Go 语言出现之前,开发者们总是面临非常艰难的抉择,究竟是使用执行速度快但是编译速度并不理想的语言(如:C++),还是使用编译速度较快但执行效率不佳的语言(如:.NET、Java),或者说开发难度较低但执行速度一般的动态语言呢?显然,Go 语言在这 3 个条件之间做到了最佳的平衡:快速编译,高效执行,易于开发。
Go 语言的发展目标
- Go 语言的主要目标是将静态语言的安全性和高效性与动态语言的易开发性进行有机结合,达到完美平衡;
- 另一个目标是对于网络通信、并发和并行编程的极佳支持,从而更好地利用大量的分布式和多核的计算机。
Go 语言的优点
- 自带垃圾回收机制
- 支持高并发
- 快速编译
- 高效执行
- 易于开发
Go 语言的缺点
- 函数不支持参数自带默认值
- []uint8 转 json 后,前端输出结果异常
Go 语言的用途
- 搭载 Web 服务器
- 游戏服务端的开发
- 高并发场景
文件扩展名与包(package)
Go 语言源文件的扩展名很显然就是 .go。
C 文件使用后缀名 .c,汇编文件使用后缀名 .s。所有的源代码文件都是通过包(packages)来组织。包含可执行代码的包文件在被压缩后使用扩展名 .a(AR 文档)。
Go 语言的标准库(第 9.1 节)包文件在被安装后就是使用这种格式的文件。
注意 当你在创建目录时,文件夹名称永远不应该包含空格,而应该使用下划线 “_” 或者其它一般符号代替。
常用命令
|
|
Go 基础知识
-
GO 工作区的文件结构。
在 GOPATH 定义的工作区下,有三个目录:bin,pkg,src。其中每一个目录都有它特殊的作用。
$GOPATH/bin 目录是 GO 用来存放通过命令 go install 编译的二进制文件的位置。
$GOPATH/pkg 放编译后的包文件,包文件名字与所在目录一样,注意:名字与 package 无关。
src 目录是所有 .go 文件或源代码的位置。
-
每个 Go 文件都属于且仅属于一个包。一个包可以由许多以 .go 为扩展名的源文件组成,因此文件名和包名一般来说都是不相同的。
你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。
属于同一个包的源文件必须全部被一起编译,一个包即是编译时的一个单元,因此根据惯例,每个目录都只包含一个包。
如果对一个包进行更改或重新编译,所有引用了这个包的客户端程序都必须全部重新编译。
标准库路径:$GOROOT/pkg/darwin_amd64
- 包的分级声明和初始化
你可以在使用 import 导入包之后定义或声明 0 个或多个常量(const)、变量(var)和类型(type),这些对象的作用域都是全局的(在本包范围内),所以可以被本包中所有的函数调用(如 gotemplate.go 源文件中的 c 和 v),然后声明一个或多个函数(func)。
包名引用方式:“test/bao” (项目名称/包文件夹名)
自定义包初始化:go mod init xxx(项目名)
- 包管理器 ToDo Something…
-
可见性规则
当标识符(包括常量、变量、类型、函数名、结构字段等等)以一个大写字母开头,如:Group1,那么使用这种形式的标识符的对象就可以被外部包的代码所使用(客户端程序需要先导入这个包),这被称为导出(像面向对象语言中的 public);标识符如果以小写字母开头,则对包外是不可见的,但是他们在整个包的内部是可见并且可用的(像面向对象语言中的 private )。
-
数据类型强制转换
1 2 3 4b := []byte("mChenys") // 字符串强转为byte切片 s := string(b) // 字节切片强制转换为字符串 str := strconv.Itoa(int(deviceId) // int转换为字符串字符串虽然在 Go 语言中是基本类型 string,但是它其实就是字符组成的数组。
byte和rune
- byte是指二进制,以二进制的形式存储到内容
- rune就是int32的别名,主要是在循环字符串时用到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15// 驼峰单词转下划线单词 func ToSnakeCase(s string) string { var output []rune for i, r := range s { if i == 0 { output = append(output, r) } else { if unicode.IsUpper(r) { output = append(output, '_') } output = append(output, r) } } return strings.ToLower(string(output)) }int大小与所在的操作系统位数有关,在32位机器上就是int32,在64位机器上就是int64【uint类似】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47// int和string互转,Atoi代表什么意思, A 就是ASCII, i就是integer,所以Atoi= ASCII to integer. ItoA= Integer to ASCII. strconv.Itoa(i int) string // 将int转换为十进制字符串形式[读法:i to a] strconv.Atoi(s string) (int, error) // 将字符串转换为十进制int [读法:a to i] // int64和string互转 i := int64(123) s := strconv.FormatInt(i, 10) // int64转十进制的string i, err := strconv.ParseInt(s, 10, 64) // 十进制string转int64,Tip: strconv.ParseInt(s string, base int, bitSize int) 的 bitSize 参数不会将字符串转换为您选择的类型, 而只是在此处将结果限制为特定的“位”,如果想要得到你要的 int 类型必须手动转换类型. // uint64和string互转 i := uint(18446744073709551615) str := strconv.FormatUint(i, 10) // uint64转string i, err := strconv.ParseUint(s, 10, 64) // string转int64 // float和string互转 v := 3.1415926535 s1 := strconv.FormatFloat(v, 'f', -1, 32) // float32转string s2 := strconv.FormatFloat(v, 'f', -1, 64) // float64转string s := "3.1415926535" v1, err := strconv.ParseFloat(v, 32) // string转float32 v2, err := strconv.ParseFloat(v, 64) // string转float64 // float和int互转 var ( luck []int leftAmountSum int leftAmount int ) num := int(float32(luck[k]) / float32(leftAmountSum) * float32(leftAmount)) // interface 转为具体的 struct type msgI interface { Set(a string) error } type msgStruct struct { A string } func (t *msgStruct) Set(a string) error { t.A = a return nil } func NewObject() msgI { return msgStruct{A: a} } msg := NewObject() s, ok := msg.(msgStruct) // interface 转为 struct,方便获取结构体内的变量 a := s.A // 等价于 a := msg.(msgStruct).A -
字节
字节(Byte)是计算机信息技术用于计量存储容量的一种计量单位,作为一个单位来处理的一个二进制数字串,是构成信息的一个小单位。最常用的字节是八位的字节,即它包含八位的二进制数。字节通常简写为“B”,而位通常简写为小写“b”。
换算:
UTF-8编码:一个英文字符等于一个字节,一个中文(含繁体)等于三个字节。中文标点占三个字节,英文标点占一个字节
Unicode编码:一个英文等于两个字节,一个中文(含繁体)等于两个字节。中文标点占两个字节,英文标点占两个字节
1 2 3 4 5 6 7 8 9 10 11// 输出中文字符 s := "中国" r := []rune(s) fmt.Println(len(r)) for i := 0; i < len(r); i++ { fmt.Printf("%x ", r[i]) } fmt.Println() for i := 0; i < len(r); i++ { fmt.Printf("%c ", r[i]) } -
常量声明 iota 枚举值
常量和变量进行大小比较时,常量类型会进行隐式转换,然后再跟变量比较。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16const ( Sunday = iota // 0 Monday // 1 Tuesday // 2 Wednesday // ... Thursday Friday Saturday ) const ( mutexLocked = 1 << iota // 1 mutexWoken // 2 mutexStarving // 4 mutexWaiterShift = iota // 3 ) -
当一个变量被声明之后,系统自动赋予它该类型的零值:int 为 0,float 为 0.0,bool 为 false,string 为空字符串,指针为 nil。记住,所有的内存在 Go 中都是经过初始化的。
-
当你在函数体内声明局部变量时,应使用简短声明语法 :=
这是使用变量的首选形式,但是它只能被用在函数体内,而不可以用于全局变量的声明与赋值。使用操作符 := 可以高效地创建一个新的变量,称之为初始化声明。
1a := 1 -
交换两个变量的值,则可以简单地使用 a, b = b, a。
(在 Go 语言中,这样省去了使用交换函数的必要)
-
指针
当程序在工作中需要占用大量的内存,或很多变量,或者两者都有,使用指针会减少内存占用和提高效率。
Go 语言的取地址符是 &,放到一个变量前使用就会返回相应变量的内存地址。
指针声明:var intP *int,一个指针变量通常缩写为 ptr。
符号 * 可以放在一个指针前,如 *intP,那么它将得到这个指针指向地址上所存储的值;这被称为反引用操作符;另一种说法是指针转移。
绝对不要用指针指向 slice。切片本身已经是一个引用类型,所以它本身就是一个指针!!
1 2 3 4 5var i1 = 5 fmt.Printf("An integer: %d, it's location in memory: %p\n", i1, &i1) // 如果我们想调用指针 intP,我们可以这样声明它 var intP *int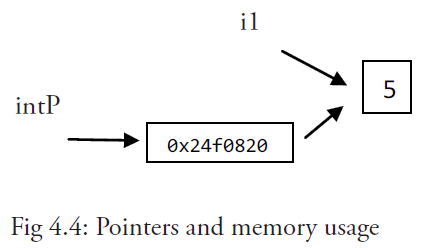
-
函数尽量使用命名返回值:会使代码更清晰、更简短,同时更加容易读懂。
1 2 3 4 5func getX2AndX3_2(input int) (x2 int, x3 int) { x2 = 2 * input x3 = 3 * input return // <=> return x2, x3 }类的方法定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35// 类型和作用在它上面定义的方法必须在同一个包里定义 func (recv receiver_type) methodName(parameter_list) (return_value_list) { ... } // 示例 package main import "fmt" // 类变量 type TwoInts struct { a int b int } func main() { two1 := new(TwoInts) two1.a = 12 two1.b = 10 fmt.Printf("The sum is: %d\n", two1.AddThem()) fmt.Printf("Add then to the param: %d\n", two1.AddToParam(20)) two2 := &TwoInts{1, 2} fmt.Printf("The sum is %d\n", two2.AddThem()) } // 类方法1 func (this *TwoInts) AddThem() int { return this.a + this.b } // 类方法2 func (this *TwoInts) AddToParam(param int) int { return this.a + this.b + param } -
空白符 _,赋值后会自动丢弃掉,不占用内存
-
关键字 defer 允许我们推迟到函数返回之前(或任意位置执行 return 语句之后)一刻才执行某个语句或函数。它一般用于释放某些已分配的资源。(关键字 defer 的用法类似于面向对象编程语言 Java 和 C# 的 finally 语句块)
规则一:当 defer 被声明时,其参数就会被实时解析
规则二:多个 defer 的执行顺序为先进后出(相当于栈的执行顺序)
defer、return、返回值三者的执行顺序应该是:return最先给返回值赋值;接着defer开始执行一些收尾工作;最后RET指令携带返回值退出函数。
-
数组&slice&map
new和make的区别 两者都是用来做内存分配的; make只用于slice、map、以及channel的初始化,返回的还是这三个引用类型本身; new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
make也用来分配内存的,区别于new,它只用于slice,map以及chan的内存创建。而且返回的类型就是这三个类型的本身,而不是它们的指针类型,因为这三种类型本身就是引用类型。所以没必要返回它们的指针类型。
何时使用 new() 和 make()『new和make的区别,前者返回的是指针,后者返回实例,且make关键字只能创建channel、slice和map这三个引用类型。』
- 切片、映射和通道,使用 make『注意 make 返回一个实例,slice 和 map 如果没有实例化,json 后直接返回 null,slice 需要实例化才能返回[]』
- 数组、结构体和所有的值类型,使用 new『注意 new 返回一个指针』
数组是具有相同 唯一类型 的一组已编号且长度固定的数据项序列,而切片是一个长度可变的数据项序列。
切片的优点:
- 长度可变的数据项序列
- 切片是引用,所以它们不需要使用额外的内存并且比使用数组更有效率,所以在 Go 代码中 切片比数组更常用。
1 2 3 4 5 6# 创建数组 arr1 := new([len]type) # 数组的初始化 var arr [len]type{key: value} arr := [len]type{key: value}1 2 3 4 5 6 7 8 9 10 11# 切片的初始化 // 初始化切片的两种方式:创建了一个长度为 10,容量为 50 的 切片 slice1,该 切片 指向数组的前 10 个元素。『如果没有指定容量,则容量等于长度』 slice1 := make([]type, start_length, capacity) var slice1 []int = make([]int, 10, 50) x := []int{2, 3, 5, 7, 11} <=> x := [5]int{2,3,5,7,11}[:] // 切片也可以用类似数组的方式初始化,这样就创建了一个长度为 5 的数组并且创建了一个相关切片。 // slice追加值 options := make([]string, 0) // 定义一个空切片,等价于 options := []string{} options = append(options, "a")1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23// 声明map var m map[int]string // 初始化map的两种方式, 未初始化的map为nil map,不能赋值 m := make(map[int]string) var m = map[string]uint8{"a": 1, "b": 2} # 创建map map1 := make(map[keytype]valuetype, cap) # map的初始化 map1 := map[keytype]valuetype{"key":"value"} // 可选择初始化 eg: map1 := map[int]string{0: "a", 1: "b"} // 在map中删除一个键 delete(map1, key1) // map 赋值示例 myMap := make(map[int64]string) myMap[1] = "value1" // 判断key是否存在map中的方法 if _, ok := myMap[key]; ok { //key存在 } -
结构体
1 2 3 4 5 6 7 8 9 10 11 12 13type T struct { field1 type1 field2 type2 ... } 创建struct t := new(T) <=> var t *T = new(T) var t T struct的初始化 t := &T{1, 2} t := T{1, 2}结构体也可以不包含任何字段,称为空结构体,struct{}表示一个空的结构体,注意,直接定义一个空的结构体并没有意义,但在并发编程中,channel之间的通讯,可以使用一个struct{}作为信号量。 空结构的优点:
- 可以和普通结构一样操作
- 不占用空间
- 声明两个空对象,它们指向同一个地址
1 2ch := make(chan struct{}) ch <- struct{}{} // 空结构对象实例化打tags: 反引号
反引号用来创建 原生的字符串字面量 ,这些字符串可能由多行组成(不支持任何转义序列),原生的字符串字面量多用于书写多行消息、HTML以及正则表达式。
1 2 3 4 5 6// 使用json:"-"定义我们告诉编码器完全跳过该字段 type User struct { UserId int `json:"user_id" form:"user_id"` UserName string `json:"user_name" form:"user_name"` Password string `json:"-" form:"-"` } -
interface
泛型编程: 如interface{}『定义一个通用的数据类型』, 不依赖于具体的数据类型的编程方式,即函数传参不限制数据类型。
接口定义了一组方法(方法集),但是这些方法不包含(实现)代码:它们没有被实现(它们是抽象的)。接口里也不能包含变量。『适用场景:定时任务』
接口的名字由方法名加 [e]r 后缀组成,例如 Printer、Reader、Writer、Logger、Converter 等等。还有一些不常用的方式(当后缀 er 不合适时),比如 Recoverable,此时接口名以 able 结尾,或者以 I 开头(像 .NET 或 Java 中那样)。
用 类型断言 来测试在某个接口 varI 是否包含某个结构体类型 T 的值
struct嵌入interface可以使得一个struct具有interface的接口,而不需要实现interface中的有声明的函数。1 2 3 4 5// 类型断言的单个返回值形式对不正确的类型将会panic。 因此,请始终使用“,ok”的习惯用法。 v, ok := varI.(T); // varI 必须是一个接口变量 if !ok { // handle the error gracefully }1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64// 示例 package main import "fmt" // 第一个结构体 type Square struct { side float32 } type Shaper interface { Area() float32 Area2(a float32) float32 } func (sq *Square) Area() float32 { return sq.side * sq.side } func (sq *Square) Area2(a float32) float32 { return sq.side + a } // 第二个结构体 type Square2 struct { width float32 } func (sq2 *Square2) Area() float32 { return sq2.width * sq2.width } func (sq2 *Square2) Area2(a float32) float32 { return sq2.width + a } func main() { // 第一个结构体 sq1 := new(Square) sq1.side = 5 // var areaIntf Shaper // areaIntf = sq1 areaIntf := Shaper(sq1) // 接口调用方式 fmt.Printf("%f\n", areaIntf.Area()) fmt.Printf("%f\n", areaIntf.Area2(3.14)) // 第二个结构体 sq2 := &Square2{5} areaIntf2 := Shaper(sq2) fmt.Printf("%f\n", areaIntf2.Area()) fmt.Printf("%f\n", areaIntf2.Area2(3.14)) // 两个结构体同时调用 interface shapes := []Shaper{sq1, sq2} for n, _ := range shapes { if ret, ok := shapes[n].(*Square); ok { // 接口动态类型判断 fmt.Printf("当前调用的结构体是:%T\n", ret) } if ret, ok := shapes[n].(*Square2); ok { fmt.Printf("当前调用的结构体是:%T\n", ret) } fmt.Println(n, shapes[n], shapes[n].Area()) } }struct 实现 interface 的方法,struct 实现了 interface 所有方法后,可以隐式声明实现了那个 interface
- var _ error = (*ClientError)(nil)
- var _ error = ClientError{}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15// ClientError 重构 error 这个内置的 interface type ClientError struct { Code ErrCode Msg string } var _ error = (*ClientError)(nil) // 隐式声明 func (e *ClientError) Error() string { return fmt.Sprintf( "ClientError { Code: %d, Msg: %#v }", e.Code, e.Msg, ) } -
空接口
空接口或者最小接口 不包含任何方法,它对实现不做任何要求:可以给一个空接口类型的变量 var val interface{} 赋任何类型的值。
1 2 3 4 5 6 7// 定义方式 1. // <=> var i interface{}, 此声明表示变量 i 可以赋值任意数据类型的值 type Element interface{} var i Element 2. type interfaceSlice []interface{} // 定义空slice接口用途:
- 构建包含不同类型变量的数组/slice
- 复制数据切片至空接口切片
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36// 构建通用类型或包含不同类型变量的数组 package main import "fmt" type Element interface{} type Vector struct { a []Element } func (p *Vector) Get(i int) Element { return p.a[i] } func (p *Vector) Set(i int, e Element) { p.a[i] = e } func main() { struct1 := &Vector{make([]Element, 10)} i := 3 struct1.Set(i, "String") fmt.Printf("index%d: %T\n", i, struct1.Get(i)) i = 1 struct1.Set(i, 120) fmt.Printf("index%d: %T\n", i, struct1.Get(i)) i = 9 struct1.Set(i, false) fmt.Printf("index%d: %T\n", i, struct1.Get(i)) fmt.Println(struct1) }1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17// 复制数据切片至空接口切片 package main import "fmt" type interfaceSlice []interface{} type myType int func main() { dataSlice := []myType{1, 2, 3} inter := make(interfaceSlice, len(dataSlice)) for i, d := range dataSlice { inter[i] = d } fmt.Println(inter) } -
反射包
反射包可以直接获取变量的数据类型和值。 实际上,反射是通过检查一个接口的值,变量首先被转换成空接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42func TypeOf(i interface{}) Type func ValueOf(i interface{}) Value // 示例 package main import ( "fmt" "reflect" ) func main() { var x float64 = 3.4 fmt.Println("type:", reflect.TypeOf(x)) fmt.Println("value:", reflect.ValueOf(x)) } func walk(x interface{}, fn func(input string)) { val := reflect.ValueOf(x) for i := 0; i < val.NumField(); i++ { field := val.Field(i) if field.Kind() == reflect.String { fn(field.String()) } } } // 数据类型判断 switch reflect.TypeOf(data).Kind() { case reflect.Map: fmt.Println("map") case reflect.Array: fmt.Println("array") case reflect.Slice: fmt.Println("slice") case reflect.Struct: fmt.Println("struct") default: fmt.Println("other) } -
协程(goroutine) & 通道(channel)
使用goroutine需注意
- 注意协程超时问题
- 注意协程并发数量控制
- 注意处理异常 recover()
GOMAXPROCS
通常,如果有 n 个核心,会设置 GOMAXPROCS 为 n-1 以获得最佳性能,但同样也需要保证,协程的数量 > 1 + GOMAXPROCS > 1。
所以如果在某一时间只有一个协程在执行,不要设置 GOMAXPROCS!
Go 协程(goroutines) & 协程(coroutines)
区别:
- Go 协程意味着并行(或者可以以并行的方式部署),协程一般来说不是这样的
- Go 协程通过通道来通信;协程通过让出和恢复操作来通信
channel
1 2 3 4 5 6 7声明方式:『通道通常应为1大小或无缓冲。』 var ch1 chan string ch1 = make(chan string, [cap]) // cap 为缓冲通道的容量 ch1 := make(chan string, [cap]) 借助函数 len(ch) 求取缓冲区中剩余元素个数, cap(ch) 求取缓冲区元素容量大小。通信操作符 <-
流向通道(发送)
ch <- int1 表示:用通道 ch 发送变量 int1(双目运算符,中缀 = 发送)
从通道流出(接收),三种方式:
int2, ok = <-ch 表示:变量 int2 从通道 ch(一元运算的前缀操作符,前缀 = 接收)接收数据(获取新值);假设 int2 已经声明过了,如果没有的话可以写成:int2 := <-ch。【channel被close()掉时才会返回非ok】
<-ch 可以单独调用获取通道的(下一个)值,当前值会被丢弃,但是可以用来验证
close(ch) // 关闭通道:使用此命令后,会保证channel中的数据会被读取完才会关闭。
【tip: 使用 for-range 语句来读取通道是更好的办法,因为这会自动检测通道是否关闭】
1 2 3 4 5// 可以将普通 channel 隐式转换成单向 channel,只收或只发,但不能将单向 channel 转换为普通 channel // 单向channel,适用于生产者消费者模式 var ch1 chan int // ch1是一个正常的channel,是双向的 var ch2 chan<- int = ch1 // ch2是单向channel,只用于写int数据 var ch3 <-chan int = ch1 // ch3是单向channel,只用于读int数据无缓冲channel与有缓冲channel的区别
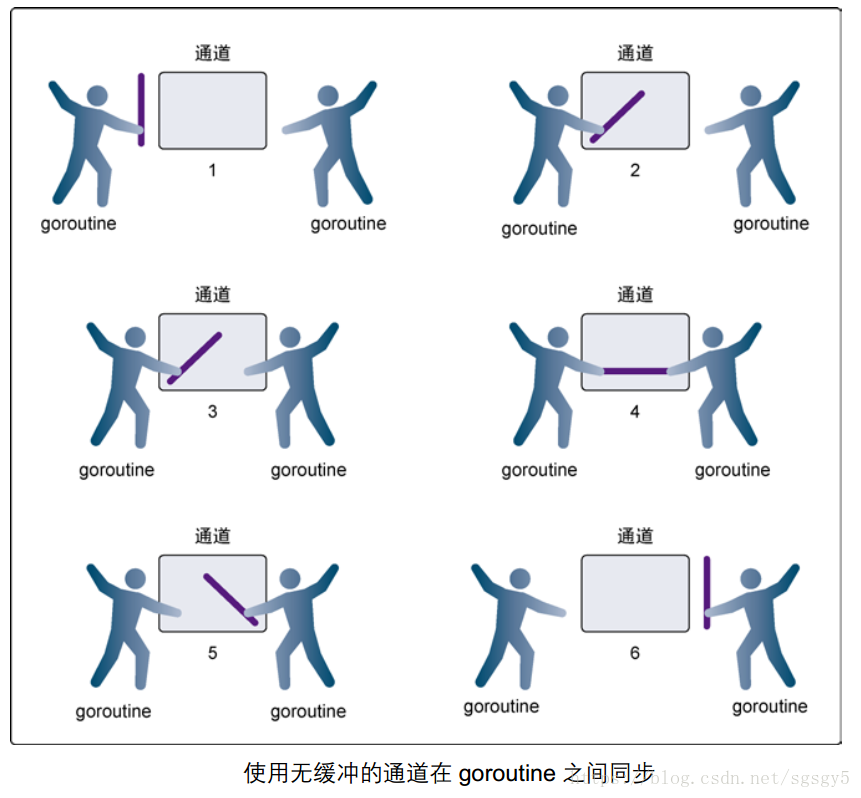
无缓冲channel是同步的(如打电话),而有缓冲channel是非同步的(如发短信)。
打电话。打电话只有等对方接收才会通,要不然只能阻塞。
发短信,不用等对方接受,只需发送过去就行。
常见面试题:用两个协程+一个channel实现交替输出1和2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33package main import ( "fmt" "time" ) func main() { num := make(chan int) go child(num) go child(num) num <- 0 time.Sleep(1 * time.Second) <-num close(num) // 让协程主动退出 time.Sleep(1 * time.Second) } func child(ch chan int) { defer recover() for { num, ok := <-ch if !ok { // channel被close掉时才会返回非ok break } fmt.Println(num%2+1) num++ time.Sleep(100 * time.Millisecond) ch <- num } }使用 select 切换协程或设置超时处理
select 语句实现了一种监听模式,通常用在(无限)循环中;在某种情况下,通过 break 语句使循环退出。
case 是随机选取,所以当 select 有两个 channel 以上满足条件时,则會随机选取其中一个 case 往下走。
如果你有多个 channel 需要读取,而读取是不间断的,就必须使用 for+select 机制来实现。
1 2 3 4 5 6 7 8 9select { case u:= <-ch1: ... case v:= <-ch2: ... ... default: // no value ready to be received ... }通过i, ok := <-c可以查看Channel的状态,判断值是零值还是正常读取的值。
1 2 3 4c := make(chan int, 10) close(c) i, ok := <-c fmt.Printf("%d, %t", i, ok) //0, false -
return、Goexit () 和 os.Exit () 对比
- return 结束当前函数,并返回指定值
- runtime.Goexit() 结束当前 goroutine, 其他的 goroutine 不受影响,主程序也一样继续运行
- os.Exit(0) 会结束当前程序,不管你三七二十一
-
字符串拼接方式推荐
-
strings.Builder // 拼接大量数据时,性能最好,不推荐被拷贝。当你试图拷贝 strings.Builder 并写入的时候,你的程序就会崩溃。
1 2 3 4 5 6var builder strings.Builder func (b *Builder) Write(p []byte) (int, error) func (b *Builder) WriteByte(c byte) error func (b *Builder) WriteRune(r rune) (int, error) func (b *Builder) WriteString(s string) (int, error) builder.String() // 获取最终的字符串 -
连接符
+: 字符串类型的拼接方式 -
fmt.Sprintf():多种数据类型的拼接方式
-
-
golang 的 init() 函数
init函数的主要作用:
- 初始化不能采用初始化表达式初始化的变量。
- 程序运行前的注册。
- 实现sync.Once功能。
- 其他
init函数的主要特点:
- init函数先于main函数自动执行,不能被其他函数调用;
- init函数没有输入参数、返回值;
- 每个包可以有多个init函数;
- 包的每个源文件也可以有多个init函数,这点比较特殊;
- 同一个包的init执行顺序,golang没有明确定义,编程时要注意程序不要依赖这个执行顺序。
- 不同包的init函数按照包导入的依赖关系决定执行顺序。
初始化顺序:变量初始化 -> init() -> main()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24package main import ( "fmt" ) var T int64 = a() func init() { fmt.Println("init in main.go ") } func a() int64 { fmt.Println("calling a()") return 2 } func main() { fmt.Println("calling main") } // 输出结果 // calling a() // init in main.go // calling main -
switch 语句中的 case 代码块会默认带上 break;也可以改写 case 为多条件判断
1 2 3 4 5 6 7 8 9 10 11func main() { isSpace := func(char byte) bool { switch char { case ' ', '\t': // 多 case 条件判断 return true } return false } fmt.Println(isSpace('\t')) // true fmt.Println(isSpace(' ')) // true } -
type 关键字
-
panic
什么时候使用 panic 呢?对于真正意外的情况,那些表示不可恢复的程序错误,例如索引越界、不可恢复的环境问题、栈溢出,我们才使用 panic
- 在程序启动的时候,如果有强依赖的服务出现故障时 panic 退出
- 在程序启动的时候,如果发现有配置明显不符合要求, 可以 panic 退出(防御编程)
- 其他情况下只要不是不可恢复的程序错误,都不应该直接 panic 应该返回 error
- 在程序入口处,例如 gin 中间件需要使用 recovery 预防 panic 程序退出
- 在程序中我们应该避免使用野生的 goroutine
- 如果是在请求中需要执行异步任务,应该使用异步 worker ,消息通知的方式进行处理,避免请求量大时大量 goroutine 创建
- 如果需要使用 goroutine 时,应该使用同一的 Go 函数进行创建,这个函数中会进行 recovery ,避免因为野生 goroutine panic 导致主进程退出
1 2 3 4 5 6 7 8 9 10 11func Go(f func()) { go func() { defer func() { if err := recovery(); err != nil { log.Printf("panic: %+v", err) } }() f() }() } -
数据类型
nil可以赋值给引用类型(除string外)、error类型和指针类型
- 值类型:int、float、bool、array、sturct等
- 引用类型:包含slice,map,channel,interface,func,string等『需要注意的是:引用类型在函数的内部可以对它的值进行修改,但是如果给形参重新赋值,重新赋值后的形参再怎么修改都不会影响外面的实参了』
- 指针类型:ptr
-
template 包是数据驱动的文本输出模板,其实就是在写好的模板中填充数据。
{{ 和 }} 中间的句号 . 代表传入模板的数据,根据传入的数据不同渲染不同的内容。. 可以代表 go 语言中的任何类型,如结构体、哈希等。至于 {{ 和 }} 包裹的内容统称为 action,分为两种类型:
数据求值(data evaluations) 控制结构(control structures)
action 求值的结果会直接复制到模板中,控制结构和我们写 Go 程序差不多,也是条件语句、循环语句、变量、函数调用等等…
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27# 加载多个模板到一个命名空间(同一个命名空间的模块可以互相引用) template.ParseFiles("header.tmpl", "content.tmpl", "footer.tmpl") # 获取传入数据的数组第一个 (index . 0).xxx # 条件语句 {{ if pipeline }} T1 {{ else if pipeline }} T0 {{ end }} # 循环语句 {{ range . }} T1 {{ else }} T0 {{ end }} # 这个 else 比较有意思,如果 pipeline 的长度为 0 则输出 else 中的内容 {{ range $index, $value := pipeline }} T1 {{ end }} # 获取容器的下标 ## 上下文,with 创建一个新的上下文环境,在此环境中的 . 与外面的 . 无关。 {{ with pipeline }} T1 {{ else }} T0 {{ end }} # 如果 pipeline 是空值则输出 T0 {{ with arg }} . # 此时 . 就是 arg {{ end }} # and tpl := "{{ and .x .y .z }}" t, _ := template.New("test").Parse(tpl) t.Execute(os.Stdout, map[string]interface{}{ "x": 1, "y": 0, "z": 3, })1 2 3 4 5 6 7 8 9 10 11 12 13 14type Api struct { IsGet bool StructName string Method string } apis := make([]*Api, 0) tpl, err := template.ParseFiles("./api_generate/api_template.tmpl") buf := bytes.NewBufferString("") err = tpl.Execute(buf, apis) // 模板和变量整合 if err != nil { err = errors.Wrap(err, "tpl.Execute failed") return } result = buf.Bytes() -
泛型编程
comparable 是 Go 语言预声明的类型,是那些可以比较(可哈希)的类型的集合,通常用于定义 map 里的 key 类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50package main import "fmt" // 泛型编程示例 func main() { ints := map[string]int64{ "first": 34, "second": 12, } floats := map[int64]float64{ 1: 35.98, 2: 26.99, } fmt.Printf("Generic Sums: %v and %v\n", SumIntsOrFloats[string, int64](ints), SumIntsOrFloats[int64, float64](floats), ) var strSlice = []string{"a", "a", "b"} var intSlice = []int{1, 1, 2} fmt.Printf("数组去重:%v and %v\n", RemoveDuplicate[string](strSlice), RemoveDuplicate[int](intSlice), ) } func SumIntsOrFloats[K string | int64, V int64 | float64](m map[K]V) V { var s V for _, v := range m { s += v } return s } type sliceValue interface { int | uint64 | string } func RemoveDuplicate[V sliceValue](a []V) []V { ret := make([]V, 0) temp := map[V]struct{}{} for _, item := range a { if _, ok := temp[item]; !ok { temp[item] = struct{}{} ret = append(ret, item) } } return ret } -
工作区模式(go work)
前提:go 使用的是多模块工作区,可以让开发者更容易同时处理多个模块的开发。在 Go 1.17 之前,只能使用 go.mod replace 指令来实现,如果你正巧是同时进行多个模块的开发,使用它可能是很痛苦的。每次当你想要提交代码的时候,都不得不删除掉 go.mod 中的 replace 才能使模块稳定的发布版本。
通常情况下,建议不要提交 go.work 文件到 git 上,因为它主要用于本地代码开发。推荐在: $GOPATH/src 路径下执行,生成 go.work 文件,这是一个全局项目都用到的文件。go.work 优先级高于 go.mod。
1 2 3 4go work init # 初始化工作区文件,用于生成 go.work 工作区文件 go work use ./example # 添加新的模块到工作区 go work edit -dropuse=./example # 删除命令 export GOWORK=off # 禁用工作区
如何表示无穷大
|
|
随机打乱数组(rand.Shuffle)
|
|