GORM
- 设置某一字段为NULL:db.Model(&foo).Where(“id=xxx”).Updates(map[string]interface{}{“created_at”: gorm.Expr(“NULL”)})
- FindInBatches():用于批量查询并处理记录,如果有使用select(),必须 select 主键(如id),否则会陷入无限循环
- Attrs(User{Age: 20}).FirstOrCreate(&user): 如果记录未找到,将使用参数创建 struct 和记录.
- Assign(User{Age: 30}).FirstOrCreate(&user): 不管记录是否找到,都将参数赋值给 struct 并保存至数据库.
数据类型建议
- 时间戳字段:建议使用 int64,因为 time.Unix() 需要 int64 类型
- 日期字段:建议使用 time.Time, 方便转换
自定义数据类型
为什么结构体中字段 string 类型时间, 和数据库不吻合?
我们发现,在连接mysql时, 有一个parseTime参数
parseTime=true 改变 数据库DATE, DATETIME值的输出类型, 从 []byte/string类型被改变为time.Time类型, 像0000-00-00 00:00:00会被转化为time.Time的零值
再看下我们的配置, parseTime参数为true, 即我们的datetime被转化time.time,
但我们定义的是字符串, 即又被转化为了字符串, 具体转化方案是这样:
DATETIME(Mysql) —–>time.Time(golang) ——> string(golang), 即这里的time.time到字符串 这一步出现了转化差异。
gorm中格式化时间的问题,通过自定义一个JSONTime的结构,来控制时间的格式
问题:时间字段格式为0001-01-01T00:00:00Z,对于 json,time.Time使用的是 time.RFC3339Nano 这种格式。通常程序中不使用这种格式。解决办法是定义自己的类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
# 自定义数据类型
// 定义一个新的时间数据类型
type JSONTime struct {
time.Time
}
// 序列化:转json时解析为毫秒时间戳
func (t JSONTime) MarshalJSON() ([]byte, error) {
ts := t.UnixNano() / 1e6
if ts < 0 {
ts = 0
}
return []byte(strconv.FormatInt(ts, 10)), nil
}
// 反序列化
func (t *JSONTime) UnmarshalJSON(data []byte) error {
val, err := strconv.ParseInt(string(data), 10, 64)
if err != nil {
return err
}
if val == 0 { // 兼容queue+gorm问题
t.Time = time.Time{}
return nil
}
t.Time = time.Unix(0, val*1e6)
return nil
}
// Value get from mysql need this function
func (t *JSONTime) Scan(v interface{}) error {
value, ok := v.(time.Time)
if ok {
*t = JSONTime{Time: value}
return nil
}
return fmt.Errorf("can not convert %v to timestamp", v)
}
// Value insert timestamp into mysql need this function.
func (t JSONTime) Value() (driver.Value, error) {
var zeroTime time.Time
if t.Time.UnixNano() == zeroTime.UnixNano() {
return nil, nil
}
return t.Time, nil
}
// 软删除
type JSONTimeDel struct {
time.Time
}
// 支持软删除查询
func (JSONTimeDel) QueryClauses(f *schema.Field) []clause.Interface {
return []clause.Interface{gorm.SoftDeleteQueryClause{Field: f}}
}
// 支持软删除
func (JSONTimeDel) DeleteClauses(f *schema.Field) []clause.Interface {
return []clause.Interface{gorm.SoftDeleteDeleteClause{Field: f}}
}
// 自定义数据类型:uint64切片
type SliceUint64 []uint64
func (t SliceUint64) Value() (driver.Value, error) {
data, err := json.Marshal(t)
return string(data), err
}
func (t *SliceUint64) Scan(v interface{}) error {
value, ok := v.([]byte)
if ok {
if len(value) == 0 {
return nil
} else {
return json.Unmarshal(value, t)
}
}
return fmt.Errorf("can not convert %v to slice", v)
}
|
常用代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
Insert/Update 时注意 所有字段的零值, 比如 0, '', false 或者其它零值,都不会保存到数据库内,但会使用他们的默认值。
如果你想避免这种情况,可以考虑使用 map 保存数据 或 指针 或 实现 Scanner/Valuer 接口
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql" // 声明使用的数据库驱动
)
db.Model(): 作用:1. 声明操作表名,2. 当做 where 条件并返回操作后的最新数据
db.Table("table_name"): 指定表名,方便使用其他结构体
db.Assign(Role{UserId: "15"}).First() // 不管是否找到对应记录,使用 Assign 值替代查询到的值
// 预加载指定列
type answer struct {
model.IntelligentAnswer
StaffName string `json:"staff_name"`
EntityName string `json:"entity_name"`
}
var answerInfo answer
model.Answer{}.Model().Preload("Solutions", func(db *gorm.DB) *gorm.DB {
// 获取指定预加载表的字段
return db.Select("id,content")
// 排序规则
return db.Order("sort_by").Order("id")
}).
First(&answerInfo, answerId)
// 查询最大数
var productRecordId uint64
_ = model.LotteryRecord{}.Model().Where("user_id=? and award_quantity=1", dto.UserId).Select("max(id)").Row().Scan(&productRecordId)
// 支持自定义 sql 表达式
func Expr(expression string, args ...interface{}) clause.Expr{} // eg: DB.Model(&product).Update("price", gorm.Expr("price * ? + ?", 2, 100))
// 字段自增或自减
db.Table("xxx").Where("id=? and quantity>0 and is_limit=?", Id, true).Update("quantity", gorm.Expr("quantity-1"))
// 字段自增2
if err := tx.Model(&model.CustomerUnlockReport{}).Clauses(clause.OnConflict{
Columns: []clause.Column{{Name: "the_date"}, {Name: "staff_id"}},
DoUpdates: clause.Assignments(map[string]interface{}{
"add_num": gorm.Expr("add_num+1"),
}),
}).Create(&report).Error; err != nil {
return err
}
// 批量插入并更新(gorm v2)
func (d *externalFollowUser) InsertOnDuplicate(data []model.ExternalFollowUser) error {
if len(data) <= 0 {
return nil
}
return d.Model().Clauses(clause.OnConflict{
Columns: []clause.Column{{Name: "open_user_id"}, {Name: "external_user_id"}},
DoUpdates: clause.AssignmentColumns([]string{
"remark",
"description",
}),
}).Create(&data).Error
}
// 支持数据库 text 类型
type TextDump struct {
Text string `gorm:"type:text"`
// ...
}
// 数据库迁移:不要自动关联外键
conn.DisableForeignKeyConstraintWhenMigrating = true
// 数据库迁移:设置表名和迁移表
_ = conn.Set("gorm:table_options", "comment 'xx表'").AutoMigrate(new(model.CustomerLog))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// 钩子
func (m *MessageTask) AfterSave(tx *gorm.DB) error {
return m.DelCache()
}
func (m *MessageTask) AfterDelete(tx *gorm.DB) error {
return m.DelCache()
}
func (m *MessageTask) DelCache() error {
if m.Id > 0 {
_ = db.Memcached().Del(m.PrimaryKey(m.Id))
}
return nil
}
// 只有这样写才能将 Id 传入 AfterSave 钩子 『TODO: 批量更新、批量删除无法将 Id 传入钩子,怎么办?』
func (d *messageTask) EditTask(dto map[string]interface{}, taskId uint64) error {
return model.MessageTask{Id: taskId}.Model().Updates(dto).Error
}
// 只有这样写才能将 Id 传入 AfterDelete 钩子
func (d *messageTask) DeleteTask(taskId uint64) error {
return model.MessageTask{}.Model().Delete(&model.MessageTask{Id: taskId}).Error
}
|
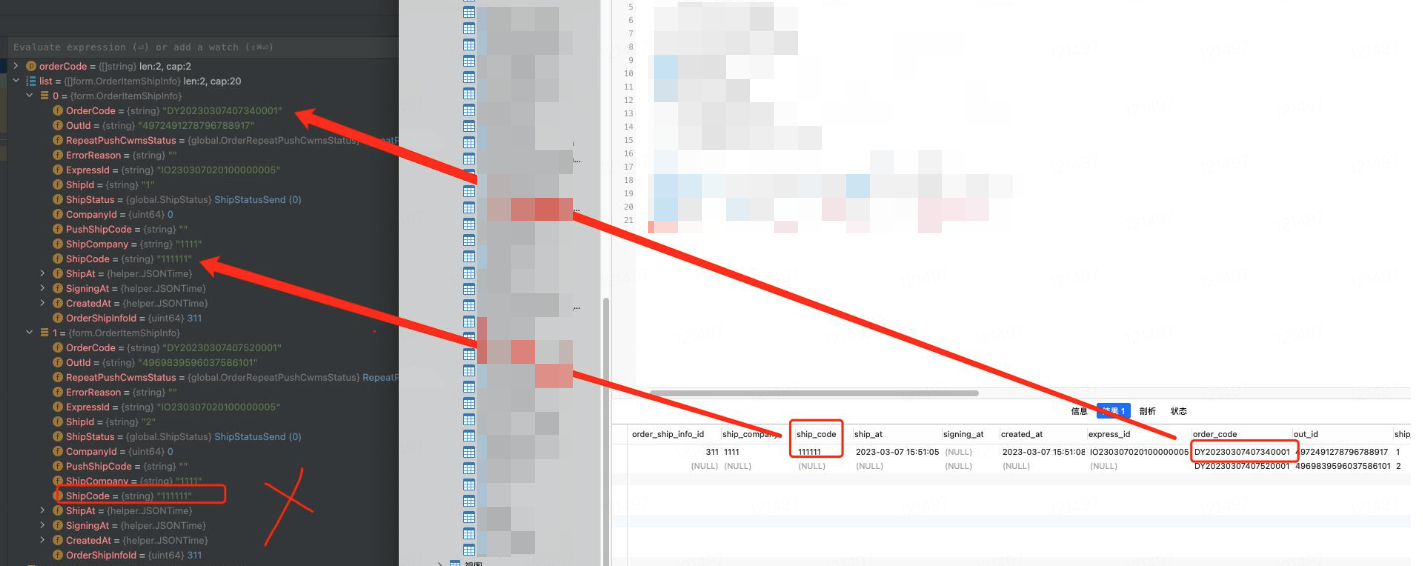
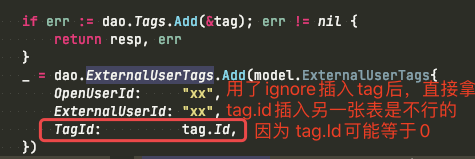
gorm create 返回的自增ID不一定靠谱
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
// 表结构
// CREATE TABLE `tags` (
// `id` bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '标签表id',
// `name` varchar(20) COLLATE utf8mb4_0900_as_cs NOT NULL DEFAULT '' COMMENT '标签名称',
// `type` tinyint unsigned NOT NULL DEFAULT '0' COMMENT '标签类型,0普通 1系统',
// `created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
// PRIMARY KEY (`id`),
// UNIQUE KEY `idx_tags_name` (`name`)
// ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_as_cs;
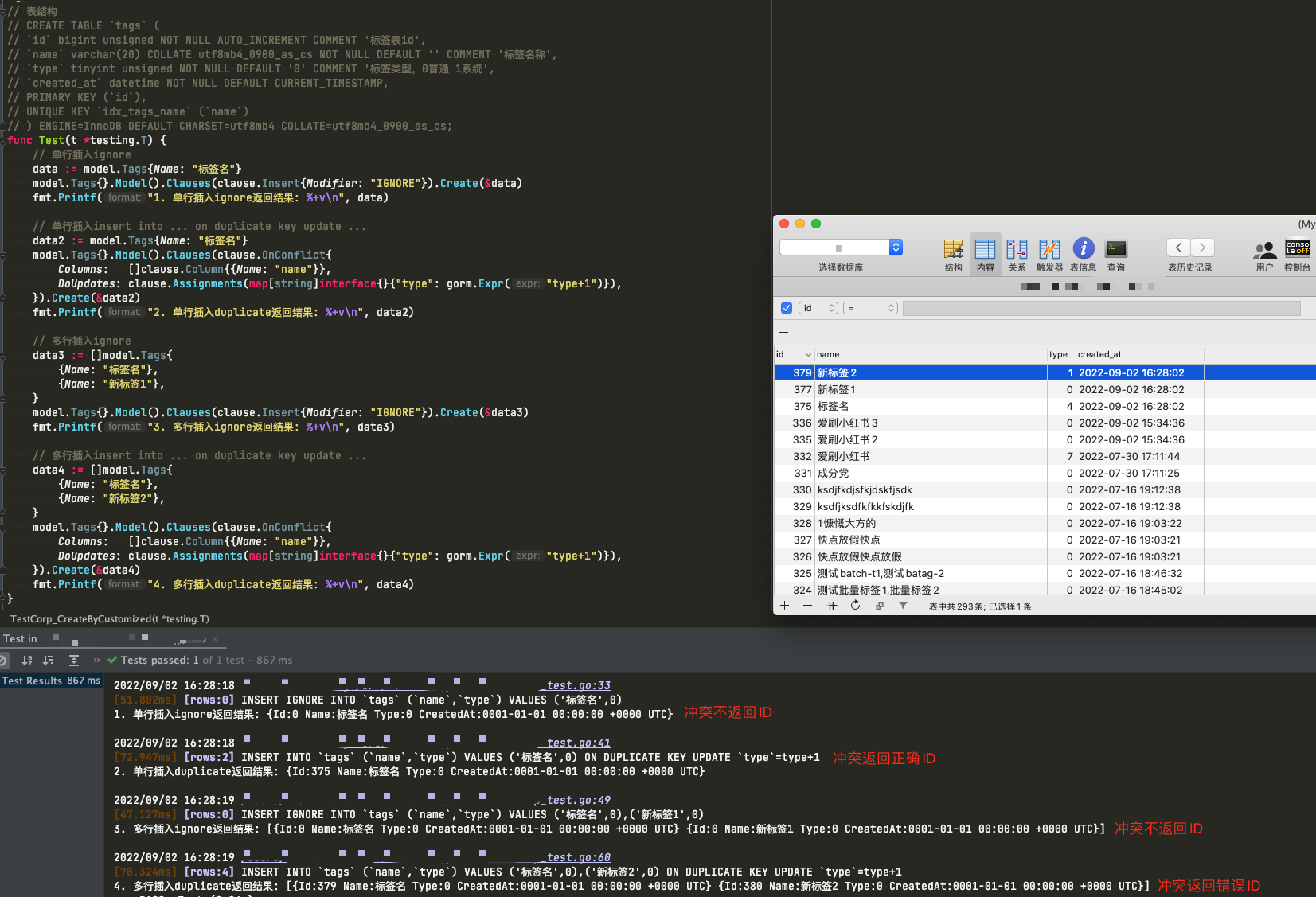
func Test(t *testing.T) {
// 单行插入ignore
data := model.Tags{Name: "标签名"}
model.Tags{}.Model().Clauses(clause.Insert{Modifier: "IGNORE"}).Create(&data)
fmt.Printf("1. 单行插入ignore返回结果: %+v\n", data)
// 单行插入insert into ... on duplicate key update ...
data2 := model.Tags{Name: "标签名"}
model.Tags{}.Model().Clauses(clause.OnConflict{
Columns: []clause.Column{{Name: "name"}},
DoUpdates: clause.Assignments(map[string]interface{}{"type": gorm.Expr("type+1")}),
}).Create(&data2)
fmt.Printf("2. 单行插入duplicate返回结果: %+v\n", data2)
// 多行插入ignore
data3 := []model.Tags{
{Name: "标签名"},
{Name: "新标签1"},
}
model.Tags{}.Model().Clauses(clause.Insert{Modifier: "IGNORE"}).Create(&data3)
fmt.Printf("3. 多行插入ignore返回结果: %+v\n", data3)
// 多行插入insert into ... on duplicate key update ...
data4 := []model.Tags{
{Name: "标签名"},
{Name: "新标签2"},
}
model.Tags{}.Model().Clauses(clause.OnConflict{
Columns: []clause.Column{{Name: "name"}},
DoUpdates: clause.Assignments(map[string]interface{}{"type": gorm.Expr("type+1")}),
}).Create(&data4)
fmt.Printf("4. 多行插入duplicate返回结果: %+v\n", data4)
}
|
gorm-bulk
gorm 的补充,支持批量插入、批量更新等【gorm2.0已支持这些功能: 利用clauses实现】
scan + left join 的坑
要用 scan + left join,必须将可能为null的字段改成 指针类型,否则数据有多条的情况下,会出现数据错乱的情况。