大数据表设计-TableStore
文章目录
简介
表格存储(Tablestore)是阿里云自研的NoSQL多模型数据库,提供海量结构化数据存储以及快速的查询和分析服务。表格存储的分布式存储和强大的索引引擎能够支持PB级存储、千万TPS以及毫秒级延迟的服务能力。
支持多种数据库模型
包括Wide column、Timeline、Timestream、Grid。
- Wide column模型:一款经典模型,目前绝大部分半结构化、结构化数据都存储在Wide column模型系统中。
- Timeline模型:表格存储自研模型,主要用于消息数据,适用于IM、Feed和物联网设备消息下推等消息系统中消息的存储和同步,目前已被广泛使用。
- Timestream模型:可应用于时序数据、时空数据等核心数据场景。
- Grid模型:可用于科学大数据的存储和查询场景。
首先说明一下为什么Tablestore的主键可以包含多个主键列,这里有几点:
- 多列主键列按照顺序共同构成一个联合主键,类似MySQL的联合
唯一索引。如果使用过HBase,可以把这里的多列主键列,拼接起来看作一个RowKey,每一列其实都只是整体主键的一部分。 - 第一列主键列是分片键,使用分片键的范围进行分片划分,保证了分片键相同的行,一定在同一个分片(Partition)上。一些功能依赖这一特性,比如分片内事务(Transection),本地二级索引(LocalIndex, 待发布),分片内自增列等。
- 业务上常需要多个字段来构成主键,如果只支持一个主键列,业务需要进行拼接,多列主键列避免了业务层做主键拼接和拆解。
- 许多用户第一次看到多列主键列时,常会有误解,认为主键的范围查询(GetRange接口)可以针对每一列单独进行,实际上这里的主键范围指的是整体主键的范围,而非单独某一列的范围。
TableStore 优缺点
优点
-
无缝扩展「单表存储能力超强!!!」
表格存储通过数据分片和负载均衡技术,实现了存储无缝扩展。随着表数据量的不断增大,表格存储会进行数据分片的调整从而为该表配置更多的存储。表格存储可支持不少于10 PB数据存储量,单表可支持不少于1 PB数据存储量或1万亿条记录。
-
查询能力强
除了支持主键查询,表格存储还支持多元索引、全局二级索引。
- 全局二级索引:相当于给主表提供了另外一种排序方式,即对查询条件预先设计了一种数据分布,可加快数据查询的效率。
- 多元索引:基于倒排索引和列式存储,支持多字段自由组合查询、模糊查询、地理位置查询、全文检索等,可解决大数据的复杂查询难题。
-
高可靠
表格存储将数据的多个备份存储在不同机架的不同机器上,并会在备份失效时进行快速恢复,提供99.99999999%(10个9)的可靠性。
-
数据强一致
表格存储保证数据写入强一致,并保证数据3副本均写入磁盘,且所有数据保持一致。写操作一旦返回成功,应用程序就能立即读到最新的数据。
-
高并发读写
表格存储支持千万级并发读写能力。
-
自带主键列递增功能(自带递增ID是用微秒时间生成的,不能保证唯一)
缺点
-
自带递增ID是用微秒时间生成的,不能保证唯一
-
搜索功能不精准『优化方案:使用最大语义匹配,针对不同搜索内容,设置最低的匹配阀值』
-
表格存储不支持两表关联查询
术语
-
数据生命周期
数据表中数据的保存时间,当数据的保存时间超过设置的数据生命周期时,系统会自动清理超过数据生命周期的数据。 数据生命周期至少为86400秒(一天)或-1(数据永不过期)。
单位为秒
-
最大版本数
数据表中的属性列能够保留数据的最大版本个数。当属性列数据的版本个数超过设置的最大版本数时,系统会自动删除较早版本的数据。
取值必须为非0整数。
设置了多元索引的表,最大版本数只能为 1。
-
数据表 & 索引表
- 索引表:对数据表中某些列数据的索引。索引表只能用于读取数据,不能写入数据。
表数据类型『TableStore interface{} type must be string/int64/float64.』
String、Integer、Double、Double
-
数据表主键 & 二元索引 & 多元索引
主键列:相当于 MySQL 的
唯一索引,主键包含的列数最大为 4 列。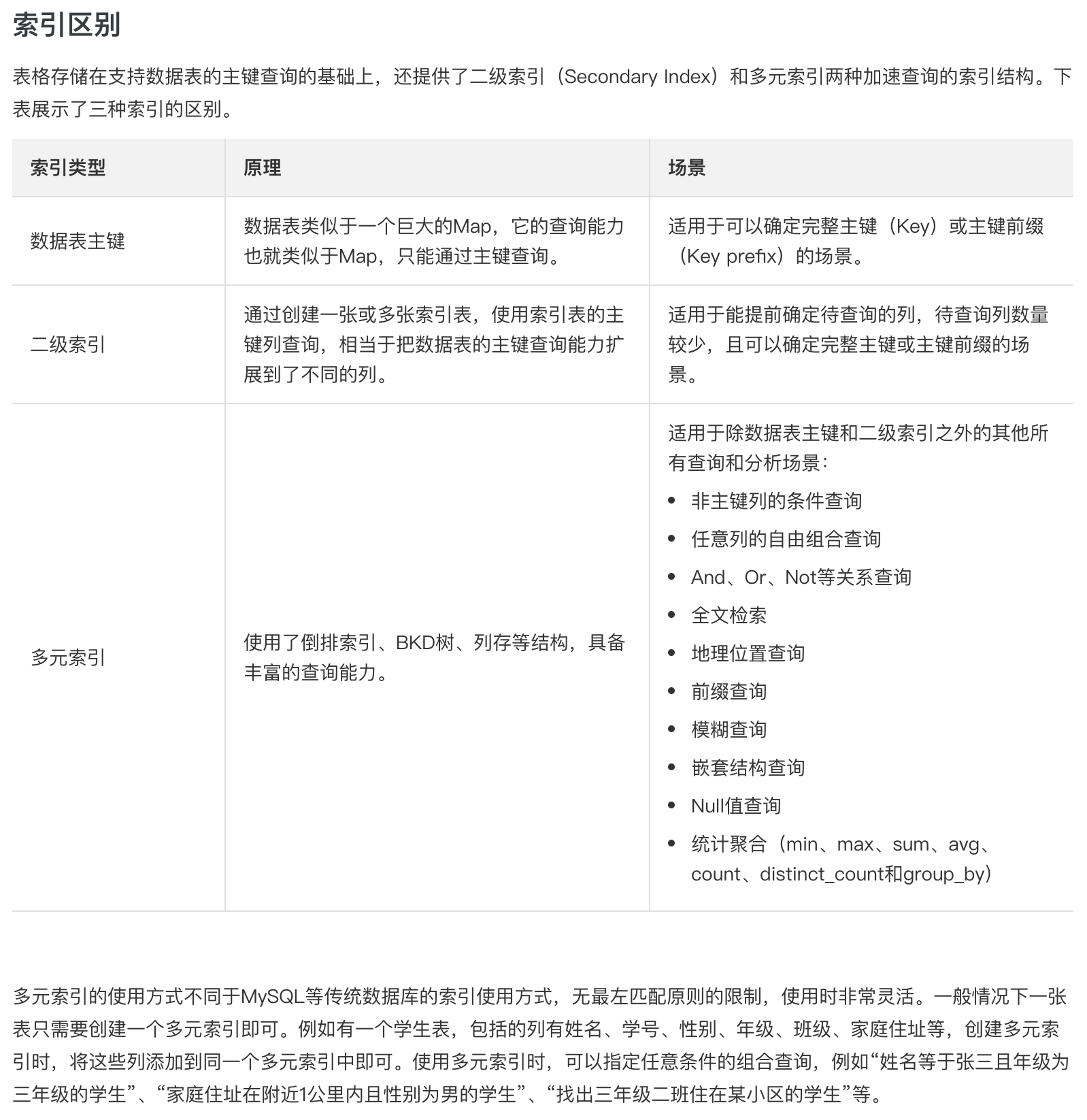
全局二级索引和本地二级索引,索引表名不能重复『不常用』

多元索引『常用』
对模糊搜索很方便。
-
多元索引『
Tablestore 的搜索/排序需求基本靠多元索引就可实现』多元索引主要用于表字段的搜索。
您可以使用CreateSearchIndex接口为主表创建一个多元索引(SearchIndex)。一张主表上可以创建多个多元索引,在创建多元索引时可以指定索引名和索引结构。
官方建议:一张表只建一个多元索引,一个多元索引包含多个字段。(此方式才能发挥多元索引最大优势,不仅功能更丰富,而且价格会更低。)
多元索引字段
Text 类型支持分词后再存储该字段所有分词的值,不支持开启EnableSortAndAgg
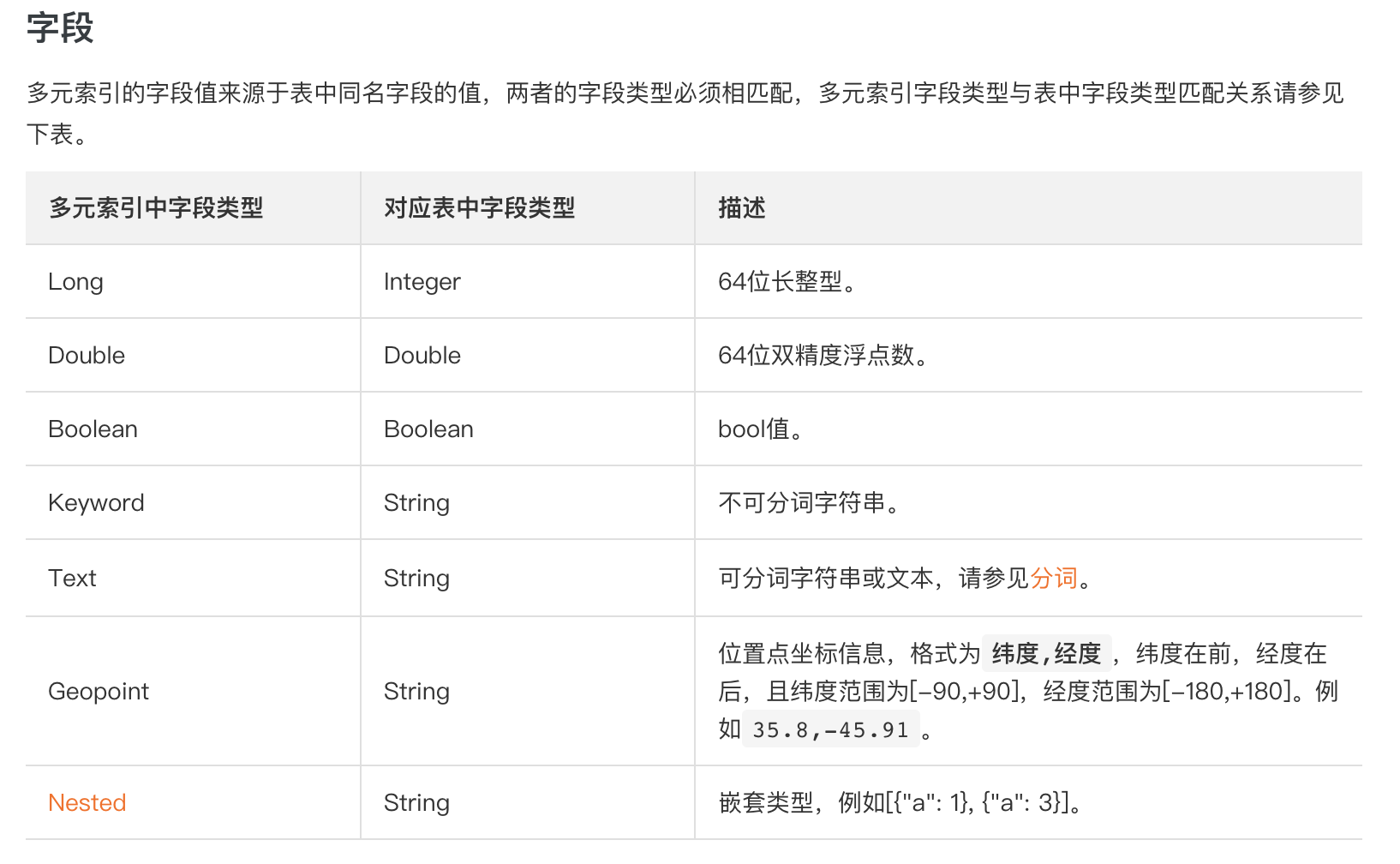
常用查询方式
-
多条件组合查询:BoolQuery查询条件包含一个或者多个子查询条件,根据子查询条件来判断一行数据是否满足查询条件。每个子查询条件可以是任意一种Query类型,包括BoolQuery。
-
精确查询:TermQuery采用完整精确匹配的方式查询表中的数据,类似于字符串匹配。对于Text类型字段,只要分词后有词条可以精确匹配即可。
-
多词精确查询:类似于TermQuery,但是TermsQuery可以指定多个查询关键词,查询匹配这些词的数据。多个查询关键词中只要有一个词精确匹配,该行数据就会被返回,等价于SQL中的In。
-
匹配查询:MatchQuery采用
近似匹配的方式查询表中的数据。对Text类型的列值和查询关键词会先按照设置好的分词器做切分,然后按照切分好后的词去查询。- Text查询关键词:当要
匹配的列为Text类型时,查询关键词会被切分成多个词,分词类型为创建多元索引时设置的分词器类型。 - MinimumShouldMatch:最小匹配个数,如果为 1 则会出现很多无相关的数据。
- Text查询关键词:当要
-
范围查询:RangeQuery根据范围条件查询表中的数据,适合于 int 型字段查询
-
通配符查询(
查询效率低):WildcardQuery通配符查询中,要匹配的值可以是一个带有通配符的字符串,目前支持星号()和问号(?)两种通配符。要匹配的值中可以用星号()代表任意字符序列,或者用问号(?)代表任意单个字符,且支持以星号()或问号(?)开头。例如查询“tablee”,可以匹配到“tablestore”。『text 类型字段是根据分词后的结果进行查询的』
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68// 通过 BoolQuery 进行多条件组合查询示例 func (c *tableStoreDB) BoolQuery() { searchRequest := &tablestore.SearchRequest{} searchRequest.SetTableName(c.TableName) searchRequest.SetIndexName(c.IndexName) // 查询条件一 rangeQuery := &search.RangeQuery{} rangeQuery.FieldName = "id" rangeQuery.GTE(1626251065881994) // 查询条件二 matchQuery := &search.MatchQuery{} matchQuery.FieldName = "col2" matchQuery.Text = "haha4" // 构造一个BoolQuery,设置查询条件是必须同时满足"查询条件一"和"查询条件二"。 boolQuery := &search.BoolQuery{ MustQueries: []search.Query{ rangeQuery, matchQuery, }, } searchQuery := search.NewSearchQuery() searchQuery.SetQuery(boolQuery) searchQuery.SetGetTotalCount(true) // 返回总数 searchQuery.SetOffset(0) searchQuery.SetLimit(2) searchQuery.SetSort(&search.Sort{ []search.Sorter{ // 按命名率排序 &search.ScoreSort{ Order: search.SortOrder_DESC.Enum(), }, // 按所有主键字段排序 &search.PrimaryKeySort{ Order: search.SortOrder_DESC.Enum(), }, // 按索引列的值排序,如果多元索引包含主键列时,主键列也可以使用这种排序方式 &search.FieldSort{ FieldName: "money", Order: search.SortOrder_DESC.Enum(), }, }, }) searchRequest.SetSearchQuery(searchQuery) // 设置为返回指定列。 searchRequest.SetColumnsToGet(&tablestore.ColumnsToGet{ // ReturnAll: true, Columns: []string{"id", "col1", "col2"}, }) searchResponse, err := c.Client.Search(searchRequest) if err != nil { fmt.Printf("%#v", err) return } fmt.Println("TotalCount: ", searchResponse.TotalCount) // 打印匹配的总行数,非返回行数。 fmt.Println("RowCount: ", len(searchResponse.Rows)) for _, row := range searchResponse.Rows { jsonBody, err := json.Marshal(row) if err != nil { panic(err) } fmt.Println("Row: ", string(jsonBody)) } } -
-
主键列 & 预定义列
- 创建表时,将非分片键的主键列设置为自增列。只有整型的主键列才能设置为自增列,系统自动生成的自增列值为64位的有符号整型。
- 设置预定义列后,在创建全局二级索引时将预定义列作为索引表的索引列或者属性列。
-
条件更新
行存在性条件:对数据表进行更改操作时,系统会先检查行存在性条件,如果不满足行存在性条件,则更改失败并给用户报错。
- IGNORE:表示忽略,不做任何存在性检查。
- EXPECT_EXIST:表示期望存在,如果该行存在,则满足条件;如果该行不存在,则不满足条件。
- EXPECT_NOT_EXIST:期望行不存在,如果该行不存在,则满足条件;如果该行存在,则不满足条件。
Timeline模型结构
todo: 这些知识点还没看懂?=_=?
Timeline模型以简单为设计目标,核心模块构成比较清晰明了。模型尽量提升使用的自由度,让您能够根据自身场景需求选择更为合适的实现。模型的架构主要包括:
- Store:Timeline存储库,类似数据库的表的概念。
- Identifier:用于区分Timeline的唯一标识。『即 Timeline ID』
- Meta:用于描述Timeline的元数据,元数据描述采用free-schema结构,可自由包含任意列。『可包含任意键值对属性』
- Queue:消息队列,一个Timeline内所有Message存储在Queue内。
- SequenceId:Queue中消息体的序列号,需保证递增、唯一。模型支持自增列、自定义两种实现模式。
- Message:Timeline内传递的消息体,是一个free-schema的结构,可自由包含任意列。『可包含任意键值对』
- Index:包含Meta Index和Message Index,可对Meta或Message内的任意列自定义索引,提供灵活的多条件组合查询和搜索。
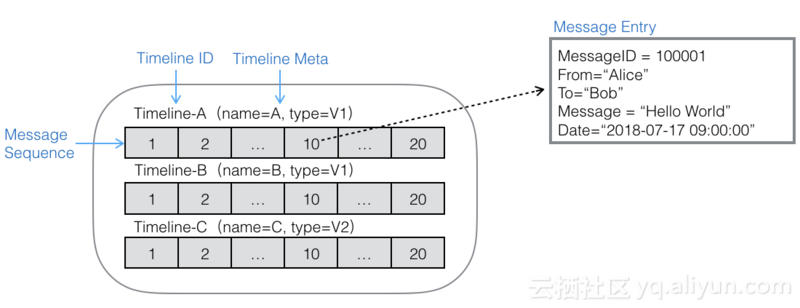
如上图是Timeline的模型图,将一张大表内的数据抽象为多个Timeline,一个大表能够承载的Timeline个数无上限。
Go SDK
-
创建表
创建表时需要指定表的结构信息(TableMeta)和配置信息(TableOptions),也可以根据需求设置表的预留读/写吞吐量(ReservedThroughput)。
参数说明
-
TableMeta
1 2 3 4 5 6 7 8 9 10TableMeta包含TableName和List。 # TableName 数据表名称。 # List 表的主键定义。 1. 表格存储可包含1个~4个主键列。主键列是有顺序的,与用户添加的顺序相同,例如PRIMARY KEY(A, B, C)与PRIMARY KEY(A, C, B)是不同的两个主键结构。表格存储会按照主键的大小为行排序,具体参见表格存储数据模型和查询操作。 2. 第一列主键作为分片键。分片键相同的数据会存放在同一个分片内,所以相同分片键下最好不要超过10 GB以上数据,否则会导致单分片过大,无法分裂。另外,数据的读/写访问最好在不同的分片键上均匀分布,有利于负载均衡。 3. 属性列(即非主键列)不需要定义。表格存储每行的数据列都可以不同,属性列的列名在写入时指定。 -
TableOptions
TableOptions包含表的TTL、MaxVersions和MaxTimeDeviation。
-
ReservedThroughtput
表的预留读/写吞吐量配置
-
IndexMetas
索引表的Meta信息。使用表格存储创建一张数据表时,可以同时为其创建多张索引表。
-