Redis
文章目录
缓存分类
众所周知,不同的缓存速度是不同的,本地内存缓存 > redis/memcache > 磁盘缓存。
PHP 可以使用静态变量(如 array)实现本地内存缓存,Golang 可以使用变量(如 map)实现本地内存缓存。
基础信息
-
Redis是一个基于内存的高效的非关系型数据库,占用端口:6379
-
Redis采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。
-
配置文件路径:/usr/local/etc/redis.conf
-
MacOs redis服务启动
To have launchd start redis now and restart at login:
brew services start redisOr, if you don’t want/need a background service you can just run:
redis-server /usr/local/etc/redis.conf -
redis-cli : 进入命令行模式。【默认无密码】 远程控制命令:redis-cli -h host -p port -a password
-
redis设置密码:config set requirepass “your password” [取消密码模式:CONFIG SET protected-mode no] 使用密码登录方式:进入redis-cli命令模式后,输入auth “your password”
-
应用场景:利用 Redis 可以实现很多架构,如维护代理池、Cookies 池、ADSL 拨号代理池、ScrapyRedis 分布式架构等
redis常用命令
建议生产环境屏蔽keys命令 没有 offset、limit 参数,一次性吐出所有满足条件的 key,万一实例中有几百 w 个 key 满足条件,当你看到满屏的字符串刷的没有尽头时,你就知道难受了。 keys 算法是遍历算法,复杂度是 O(n),如果实例中有千万级以上的 key,这个指令就会导致 Redis 服务卡顿,所有读写 Redis 的其它的指令都会被延后甚至会超时报错因为 Redis 是单线程程序,顺序执行所有指令,其它指令必须等到当前的 keys 指令执行完了才可以继续。 所以要用 scan 代替 keys *
-
dbsize: 当前库key的数量
-
select 1: 切换到库 1
-
keys *: 查看当前库已存在的所有key
-
del key:删除一个key
-
ttl key (以秒为单位)或 pttl key (以毫秒为单位)来查看 key 还有多久过期。[-1 表示永不过期]
-
info: 查看 redis 基本信息,包含多少库,多少 keys
-
keys pattern:返回满足给定pattern的所有key,eg: keys third_app*
-
help cmd: 查看cmd帮助,例如:help quit
-
exists key:确认一个key是否存在
-
type key:返回值的类型
-
RPOPLPUSH source destination 【安全队列】 命令 RPOPLPUSH 在一个原子时间内,执行以下两个动作: 将列表 source 中的最后一个元素(尾元素)弹出,并返回给客户端。 将 source 弹出的元素插入到列表 destination ,作为 destination 列表的的头元素。
-
flushdb // 删除当前数据库中的所有Key
-
flushall // 删除所有数据库中的key
-
expire key seconds:设置 key 在 n 秒后过期。
scan
SCAN cursor [MATCH pattern] [COUNT count]
基于游标的迭代器,限制查询 keys 的数量。 count 不是限定返回结果的数量,而是限定服务器单次遍历的字典槽位数量(约等于)。如果将 count 设置为 10,你会发现返回结果是空的,但是游标值不为零,意味着遍历还没结束。
scan 指令是一系列指令,除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。
- hscan 遍历 hash 字典的元素、
- sscan 遍历 set 集合的元素。
- zscan 遍历 zset 集合元素,
命令 Example
```sh
scan 0 match * count 1
hscan hash1 0 match * count 1
sscan s 0 match * count 1
zscan z 0 match * count 1
```
大 key 扫描
有时候会因为业务人员使用不当,在 Redis 实例中会形成很大的对象,比如一个很大的 hash,一个很大的 zset 这都是经常出现的。
这样的对象对 Redis 的集群数据迁移带来了很大的问题,因为在集群环境下,如果某个 key 太大,会让数据导致迁移卡顿。
另外在内存分配上,如果一个 key 太大,那么当它需要扩容时,会一次性申请更大的一块内存,这也会导致卡顿。
如果这个大 key 被删除,内存会一次性回收,卡顿现象会再一次产生。
在平时的业务开发中,要尽量避免大 key 的产生。
如果你观察到 Redis 的内存大起大落,这极有可能是因为大 key 导致的,这时候你就需要定位出具体是那个 key,
进一步定位出具体的业务来源,然后再改进相关业务代码设计。
那如何定位大 key 呢?
为了避免对线上 Redis 带来卡顿,这就要用到 scan 指令,对于扫描出来的每一个 key,使用 type 指令获得 key 的类型,
然后使用相应数据结构的 size 或者 len 方法来得到它的大小,对于每一种类型,保留大小的前 N 名作为扫描结果展示出来。
上面这样的过程需要编写脚本,比较繁琐,不过 Redis 官方已经在 redis-cli 指令中提供了这样的扫描功能,我们可以直接拿来即用。
```sh
// 查找大 key 命令:这个指令每隔 100 条 scan 指令就会休眠 0.1s
redis-cli --bigkeys -i 0.1
```
需要注意的是,这个 bigkeys 得到的最大,不一定是最大。
说明下 bigkeys 的原理你就知道了,通过 scan 命令遍历,各种不同数据结构的 key,分别通过不同的命令得到最大的 key:
- 如果是 string 结构,通过 strlen 判断;
- 如果是 list 结构,通过 llen 判断;
- 如果是 hash 结构,通过 hlen 判断;
- 如果是 set 结构,通过 scard 判断;
- 如果是 sorted se t结构,通过 zcard 判断。
发布订阅模型(Pub/Sub)
当你在使用 Pub/Sub 时,一定要注意:消费者必须先订阅队列,生产者才能发布消息,否则消息会丢失。
- publish: 发布一个消息到一个指定频道
- subscribe:订阅一个指定频道,当频道有新消息时,直接获取
- unsubscribe: 取消订阅一个指定频道
一个完整的发布、订阅消息处理流程(整个过程中,没有任何的数据存储,一切都是实时转发的。)
- 消费者订阅指定队列,Redis 就会记录一个映射关系:队列->消费者
- 生产者向这个队列发布消息,那 Redis 就从映射关系中找出对应的消费者,把消息转发给它
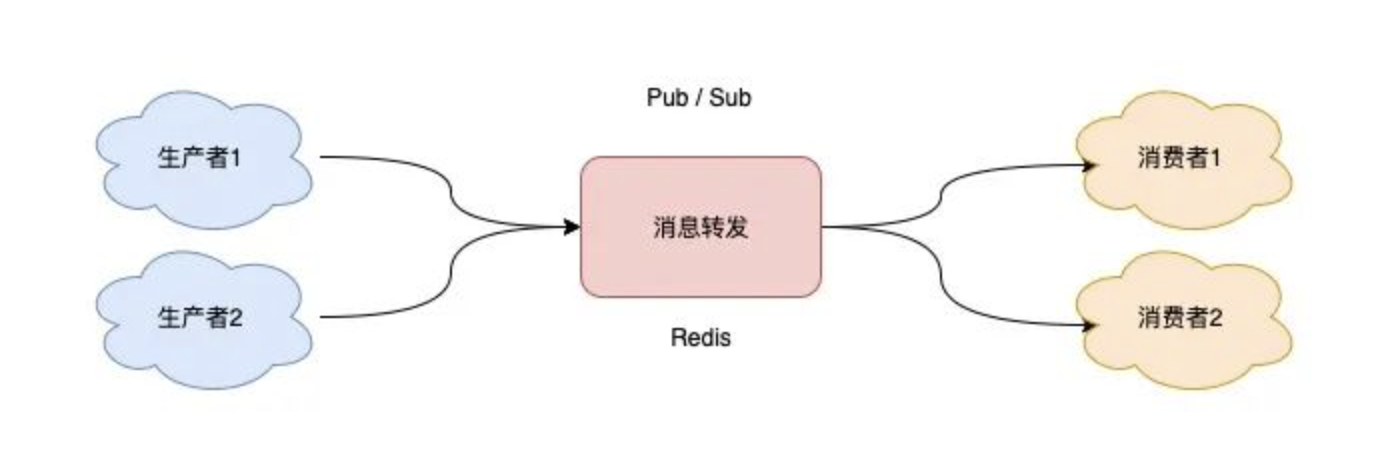
优缺点
-
最大的优势就是,支持多组生产者、消费者处理消息(也支持多个消费者同时消费同一条消息)
-
最大问题是:丢数据。
- 消费者下线,数据会丢失
- 不支持数据持久化,Redis 宕机数据也会丢失
- 消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失
有没有发现,除了第一个是优点之外,剩下的都是缺点。所以,很多人觉得 Pub/Sub 很「鸡肋」。
List队列 vs 发布订阅模型(Pub/Sub) vs Redis Stream
List 是属于「拉」模型,而 Pub/Sub 其实属于「推」模型。
- List 中的数据可以一直积压在内存中,消费者什么时候来「拉」都可以。
- 但 Pub/Sub 是把消息先「推」到消费者在 Redis Server 上的缓冲区中,然后等消费者再来取。
- Redis Stream 是 发布订阅模型(Pub/Sub) 的升级版,主要用于消息队列(MQ,Message Queue)。Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
常用案例
```php
// 设置缓存当天生效
now := time.Now()
expiration := time.Date(now.Year(), now.Month(), now.Day(), 23, 59, 59, 0, time.Local).Add(time.Second).Sub(now)
db.Redis(db.DefaultRedis).Expire(key, expiration)
// 设置一个带有生存时间和互斥锁的 key
// 字符串:SET key value [EX seconds] [PX milliseconds] [NX|XX]
function setTTLKey($key, $timeout = 300)
{
if ((Redis::connection('default'))->set($key, 1, 'ex', $timeout, 'nx')) {
return true;
}
return false;
}
// 使用 sexnx 做互斥锁需注意:由于 setnx 和 expire 是分开两步进行的操作,不具有原子性。如果客户端在执行完 setnx 后崩溃了,那么就没有机会执行 expire 了,导致它一直持有该锁。
$redis = Redis::connection();
$currentTime = time();
$cacheKey = 'subject:activate:more:' . \Auth::id();
$ttl = 60;
$errorMsg = '一分钟内只能发一次,请稍后再试';
if (($lockTime = $redis->get($cacheKey)) && ($currentTime - $lockTime >= $ttl)) {
$redis->del([$cacheKey]);
}
if ($redis->setnx($cacheKey, $currentTime) == 0) {
return $this->message($errorMsg);
}
$redis->expire($cacheKey, $ttl);
```
redis的持久化
Redis为持久化提供了两种方式:
- RDB:在指定的时间间隔能对你的数据进行快照存储。
- AOF:记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据。
性能与实践
RDB的快照、AOF的重写都需要fork,这是一个重量级操作,会对Redis造成阻塞。因此为了不影响Redis主进程响应,我们需要尽可能降低阻塞。
- 降低fork的频率,比如可以手动来触发RDB生成快照、与AOF重写;
- 控制Redis最大使用内存,防止fork耗时过长;
- 使用更牛逼的硬件;
- 合理配置Linux的内存分配策略,避免因为物理内存不足导致fork失败。
在线上我们到底该怎么做?这里提供一些实践经验。
- 如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,可以关闭持久化,如果丢失数据可以通过其它途径补回;
- 自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
- 单机如果部署多个实例,要防止多个机器同时运行持久化、重写操作,防止出现内存、CPU、IO资源竞争,让持久化变为串行;
- 可以加入主从机器,利用一台从机器进行备份处理,其它机器正常响应客户端的命令;
- RDB持久化与AOF持久化可以同时存在,配合使用。
redis 和 memcached 对比
-
redis 和 memcached 内存使用效率对比
- 使用简单的key-value存储的话,Memcached的内存利用率更高,
- 而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。
-
redis 和 memcached 存储数据类型对比
- redis支持5种数据类型,分别是string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。 整型值/浮点数和布尔值并不在其中。存储整型/浮点数时,redis会将其转换为字符串,但存储布尔值时,redis不会将其转换为字符串。「注意:Redis在string类型上会消耗较多内存」
- 而memcached存储整数/浮点数或布尔值时,不会将其转换为字符串。
-
value大小不同
- memcache是一个内存缓存,key的长度小于250字符,单个item存储要小于1M,不适合虚拟机使用
- redis单个value的最大限制是1GB
-
cpu利用
- Memcached是多核多线程,单实例吞吐量极高,可以达到几十万QPS
- redis是单核单线程,可以开启多个redis进程。redis使用的是单线程模型,保证了数据按顺序提交
-
持久化数据
- memcached 不支持
- redis 支持
redis 和 memcached 搭配使用
在不考虑扩展性和持久性的情况下,只存储kv格式的数据,建议使用memcache
在 memcached 不满足缓存需求时,再使用 redis