Mysql高级知识
文章目录
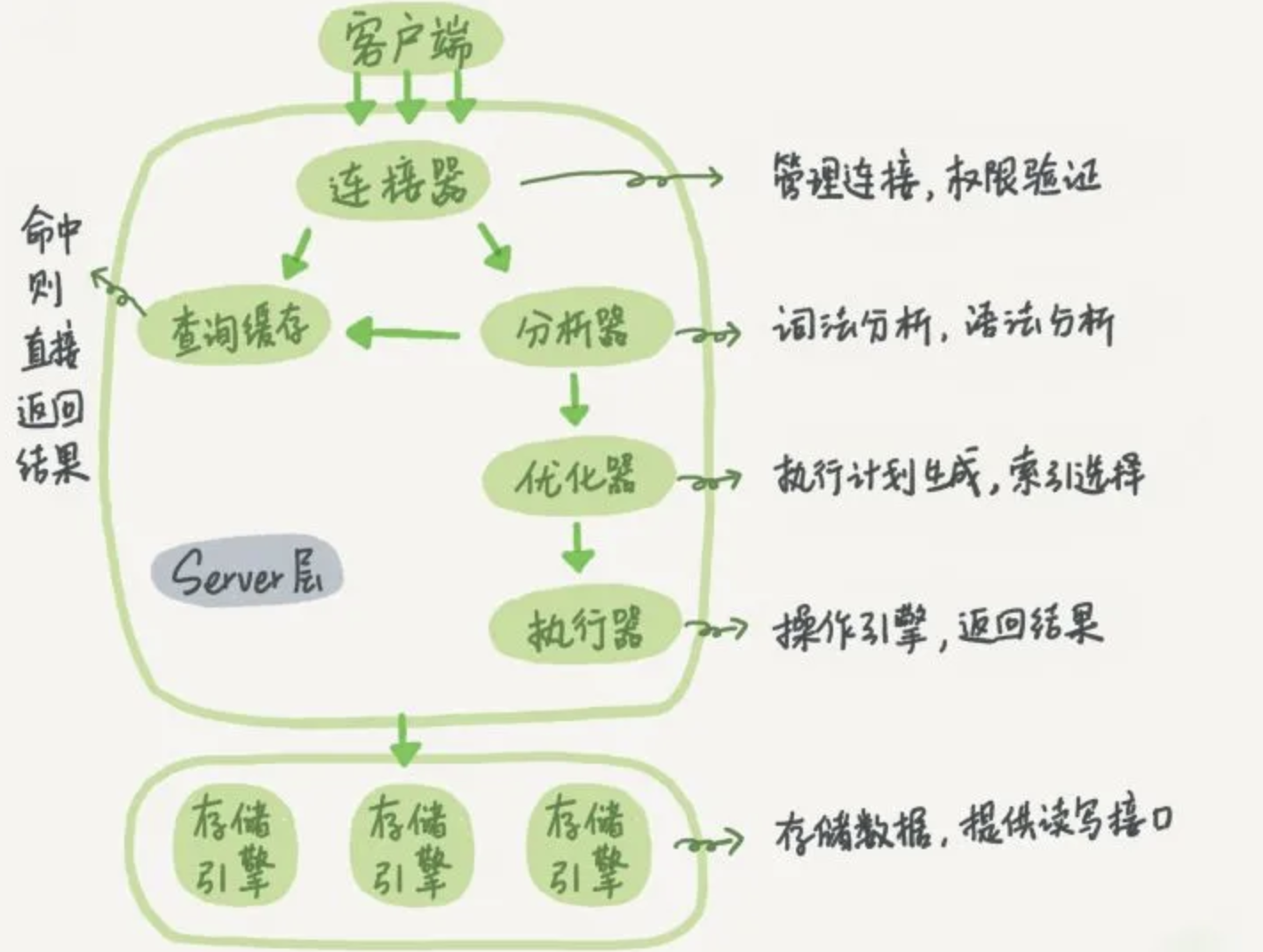
MySQL 架构
连接层:最上层是一些客户端和连接服务。主要完成一些类似于连接处理、授权认证、及相关的安全方案。在该层上引入了线程池的概念,为通过认证安全接入的客户端提供线程。同样在该层上可以实现基于SSL的安全链接。服务器也会为安全接入的每个客户端验证它所具有的操作权限。
服务层:第二层服务层,主要完成大部分的核心服务功能, 包括查询解析、分析、优化、缓存、以及所有的内置函数,所有跨存储引擎的功能也都在这一层实现,包括触发器、存储过程、视图等
引擎层:第三层存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有的功能不同,这样我们可以根据自己的实际需要进行选取
存储层:第四层为数据存储层,主要是将数据存储在运行于该设备的文件系统之上,并完成与存储引擎的交互
联想提问问题:画出 MySQL 架构图? or MySQL 的查询流程具体是? or 一条SQL语句在MySQL中如何执行的?
客户端请求 —> 连接器(验证用户身份,给予权限) —> 查询缓存(存在缓存则直接返回,不存在则执行后续操作) —> 分析器(对SQL进行词法分析和语法分析操作) —> 优化器(主要对执行的sql优化选择最优的执行方案方法) —> 执行器(执行时会先看用户是否有执行权限,有才去使用这个引擎提供的接口) —> 去引擎层获取数据返回(如果开启查询缓存则会缓存查询结果)
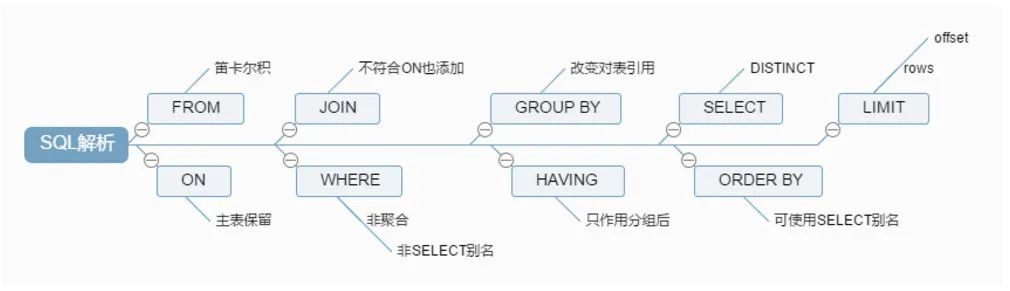
MySQL 多表连接执行顺序

多表连接采用『驱动表』策略:
何谓驱动表,指多表关联查询时,第一个被处理的表,亦可称之为基表,然后再使用此表的记录去关联其他表。
驱动表的选择遵循一个原则:在对最终结果集没影响的前提下,优先选择结果集最少的那张表作为驱动表。
连表顺序,不是两两联合之后,再去联合第三张表,而是驱动表的一条记录穿到底,匹配完所有关连表之后,再取驱动表的下一条记录重复连表操作。
多表连接并过滤条件完毕后,再执行 order by 、limit 等操作。
Mysql 执行顺序
存储引擎
InnoDB 对比 MyISAM
| 对比项 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表,不适合高并发的操作 | 行锁,操作时只锁某一行,不对其它行有影响,适合高并发的操作 |
| 缓存 | 只缓存索引,不缓存真实数据 | 不仅缓存索引还要缓存真实数据,对内存要求较高,而且内存大小对性能有决定性的影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | 是 | 是 |
一张表,里面有ID自增主键,当insert了17条记录之后,删除了第15,16,17条记录,再把Mysql重启,再insert一条记录,这条记录的ID是18还是15 ?
如果表的类型是MyISAM,那么是18。因为MyISAM表会把自增主键的最大ID 记录到数据文件中,重启MySQL自增主键的最大ID也不会丢失;
如果表的类型是InnoDB,那么是15。因为InnoDB 表只是把自增主键的最大ID记录到内存中,所以重启数据库或对表进行OPTION操作,都会导致最大ID丢失。
哪个存储引擎执行 select count(*) 更快,为什么?
MyISAM更快,因为MyISAM内部维护了一个计数器,可以直接调取。
-
在 MyISAM 存储引擎中,把表的总行数存储在磁盘上,当执行 select count(*) from t 时,直接返回总数据。
-
在 InnoDB 存储引擎中,跟 MyISAM 不一样,没有将总行数存储在磁盘上,当执行 select count(*) from t 时,会先把数据读出来,一行一行的累加,最后返回总数量。
InnoDB 中 count(*) 语句是在执行的时候,全表扫描统计总数量,所以当数据越来越大时,语句就越来越耗时了,为什么 InnoDB 引擎不像 MyISAM 引擎一样,将总行数存储到磁盘上?这跟 InnoDB 的事务特性有关,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的。
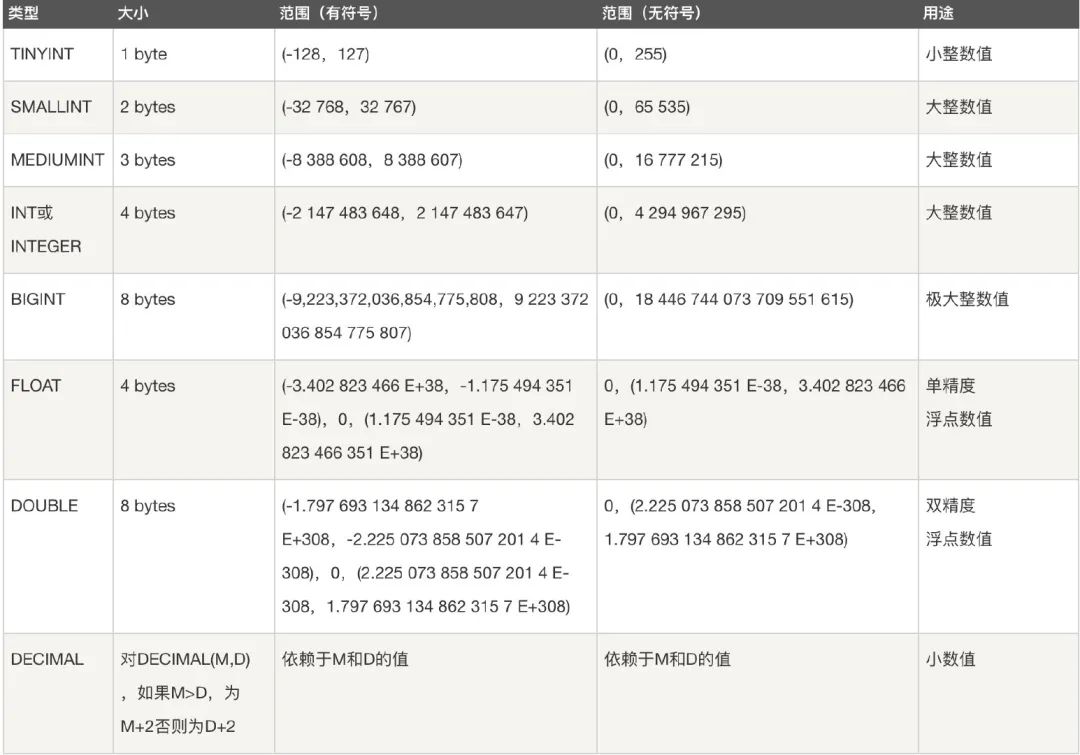
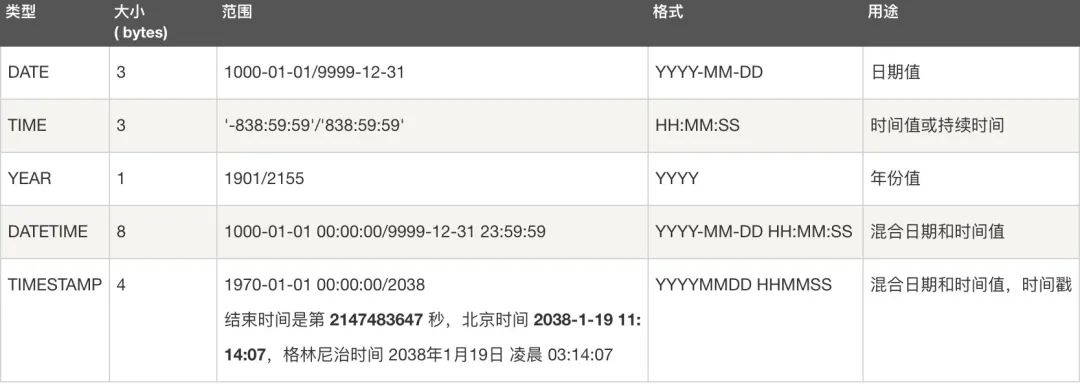
数据类型
BLOB和TEXT有什么区别?
BLOB是一个二进制对象,可以容纳可变数量的数据。有四种类型的BLOB:TINYBLOB、BLOB、MEDIUMBLO和 LONGBLOB
TEXT是一个不区分大小写的BLOB。四种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。
BLOB 保存二进制数据(如图片、声音),TEXT 保存字符数据。
索引
优势
- 提高数据检索效率,降低数据库IO成本
- 降低数据排序的成本,降低CPU的消耗
劣势
- 索引也是一张表,保存了主键和索引字段,并指向实体表的记录,所以也需要占用内存
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段, 都会调整因为更新所带来的键值变化后的索引信息
索引分类
-
从数据结构角度:B+树索引,Hash索引,Full-Text全文索引,R-Tree索引
-
从逻辑角度:
1 2 3 4 5> - 主键索引:主键索引是一种特殊的唯一索引,不允许有空值 > - 普通索引或者单列索引:每个索引只包含单个列,一个表可以有多个单列索引 > - 多列索引(复合索引、联合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀原则,* 且联合索引的字段可以是任意顺序的 * > - 唯一索引或者非唯一索引 > - 空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
建索引案例
-
hash索引
利用 CRC32() 创建 hash 字段索引,查询性能稳定,有额外的存储和计算消耗,不支持范围扫描。
CRC全称为Cyclic Redundancy Check,又叫循环冗余校验。CRC32是CRC算法的一种,常用于校验网络上传输的文件。
CRC32的基本特征:1.CRC32函数返回值的范围是0-4294967296(2的32次方减1),2.相比MD5,CRC32函数很容易碰撞
-
前缀索引、后缀索引
对一个长字符串类型的字段A,如果需要做查询功能,整个字段A加索引的话则很浪费存储空间,此时可以考虑建一个短字符串字段B并加上索引,
前缀索引:截取字段A前几个字符
后缀索引:截取字段A后几个字符
选择前缀/后缀长度的原则是:区分度高 + 占用空间少,常用的字符长度为4,具体可以执行 sql 后再选择:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15-- 前缀索引截取长度判断 SELECT count( DISTINCT LEFT ( FieldA, 3 ) ) AS L3, count( DISTINCT LEFT ( FieldA, 4 ) ) AS L4, count( DISTINCT LEFT ( FieldA, 5 ) ) AS L5, count( FieldA ) AS all FROM t; -- 后缀索引截取长度判断 SELECT count( DISTINCT RIGHT ( FieldA, 3 ) ) AS L3, count( DISTINCT RIGHT ( FieldA, 4 ) ) AS L4, count( DISTINCT RIGHT ( FieldA, 5 ) ) AS L5, count( FieldA ) AS all FROM t;
哪些情况需要创建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段
- 查询中与其他表关联的字段,外键关系建立索引
- 单键/组合索引的选择问题,高并发下倾向创建组合索引
- 查询中排序的字段,排序字段通过索引访问大幅提高排序速度
- 查询中统计或分组字段
哪些情况不要创建索引
- 表记录太少
- 经常增删改的表
- 数据重复且分布均匀的表字段,只应该为最经常查询和最经常排序的数据列建立索引(如果某个数据类包含太多的重复数据,建立索引没有太大意义)
- 频繁更新的字段不适合创建索引(会加重IO负担)
- where条件里用不到的字段不创建索引
MySQL 查询
count(*) 和 count(1)和count(列名)区别
执行效果上:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略列值为NULL
- count(1)包括了所有列,用1代表代码行,在统计结果的时候,不会忽略列值为NULL
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是只空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
- 列名为主键,count(列名)会比count(1)快,列名不为主键,count(1)会比count(列名)快『如果有主键,则 select count(主键)的执行效率是最优的』
- 如果表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
- 如果表只有一个字段,则 select count(*) 最优。
总结:count(主键) 优于 count(1) 优于 count(*)
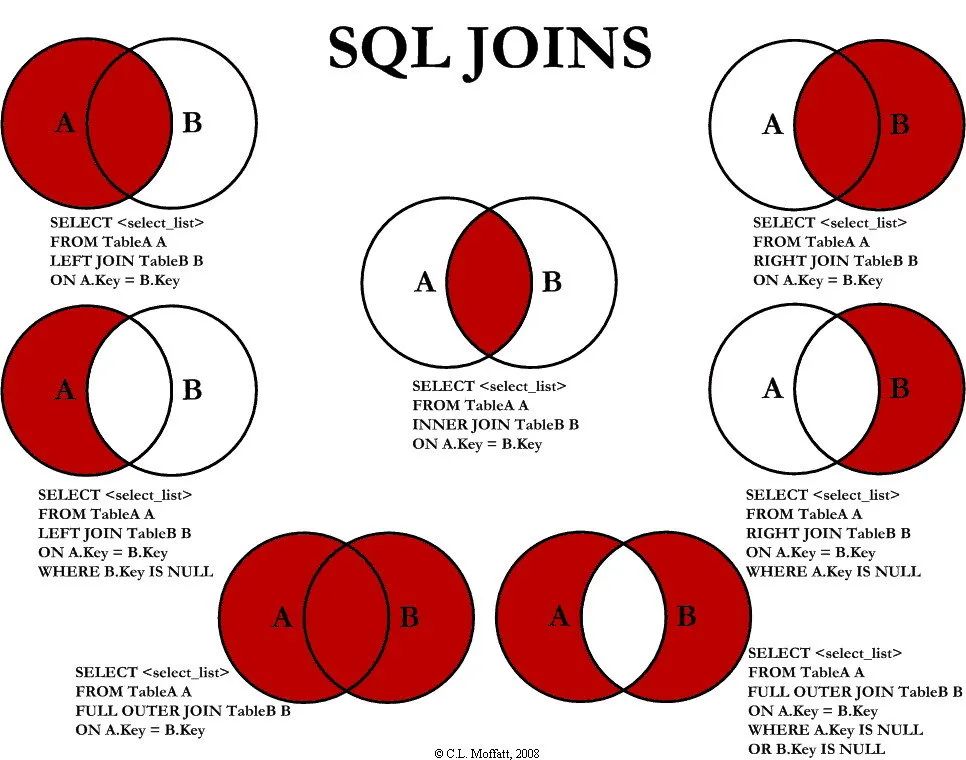
mysql 的内连接、左连接、右连接有什么区别?什么是内连接、外连接、交叉连接、笛卡尔积呢?
性能分析
MySQL常见性能分析手段
在优化MySQL时,通常需要对数据库进行分析,常见的分析手段有慢查询日志,EXPLAIN 分析查询,profiling分析以及show命令查询系统状态及系统变量,通过定位分析性能的瓶颈,才能更好的优化数据库系统的性能。
性能下降SQL慢 执行时间长 等待时间长 原因分析
- 查询语句写的烂
- 索引失效(单值、复合)
- 关联查询太多join(设计缺陷或不得已的需求)
- 服务器调优及各个参数设置(缓冲、线程数等)
性能瓶颈定位
我们可以通过 show 命令查看 MySQL 状态及变量,找到系统的瓶颈:
|
|
Explain(执行计划)
是什么:使用 Explain 关键字可以模拟优化器执行SQL查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的。分析你的查询语句或是表结构的性能瓶颈
能干吗:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
怎么玩:
- Explain + SQL语句
- 执行计划包含的信息(如果有分区表的话还会有partitions)

type 字段解释:
(显示查询使用了哪种查询类型,从最好到最差依次排列 system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL )
tip: 一般来说,得保证查询至少达到range级别,最好到达ref
- system:表只有一行记录(等于系统表),是 const 类型的特例,平时不会出现
- const:表示通过索引一次就找到了,const 用于比较 primary key 或 unique 索引,因为只要匹配一行数据,所以很快,如将主键置于 where 列表中,mysql 就能将该查询转换为一个常量
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常见于主键或唯一索引扫描
- ref:非唯一性索引扫描,范围匹配某个单独值得所有行。本质上也是一种索引访问,他返回所有匹配某个单独值的行,然而,它可能也会找到多个符合条件的行,多以他应该属于查找和扫描的混合体
- range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是在你的where语句中出现了between、<、>、in等的查询,这种范围扫描索引比全表扫描要好,因为它只需开始于索引的某一点,而结束于另一点,不用扫描全部索引
- index:Full Index Scan,index于ALL区别为index类型只遍历索引树。通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)
- ALL:Full Table Scan,将遍历全表找到匹配的行
索引优化
- 全值匹配我最爱
- 最佳左前缀法则,比如建立了一个联合索引(a,b,c),那么其实我们可利用的索引就有(a), (a,b), (a,b,c)
- 不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
- 存储引擎不能使用索引中范围条件右边的列
- 尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select i- s null ,is not null 也无法使用索引
- like “xxxx%” 是可以用到索引的,like “%xxxx” 则不行(like “%xxx%” 同理)。like以通配符开头(’%abc…’)索引失效会变成全表扫描的操作,
- 字符串不加单引号索引失效
- 少用or,用它来连接时会索引失效
- <,<=,=,>,>=,BETWEEN,IN 可用到索引,<>,not in ,!= 则不行,会导致全表扫描
一般性建议
-
对于单键索引,尽量选择针对当前query过滤性更好的索引
-
在选择组合索引的时候,当前Query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
-
在选择组合索引的时候,尽量选择可以能够包含当前query中的where字句中更多字段的索引
-
尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的
-
少用Hint强制索引
sql长度限制与占位符限制问题区分
- show variables like ‘max_allowed_packet’; sql 长度限制
- 1390: Prepared statement contains too many placeholders: MySQL预处理占位符数量限制65535。 插入m条数据n个?的占位符限制为 m*n<=65535, 或者IN查询占位符<=65535
mysql5.7.8 开始支持 json 字段查询

JSON 类型的优点
- JSON 类型在 MySQL 内部以特殊的二进制方式存放,类似于 PostgreSQL 的 JSONB 类型。最大占用空间和 longtext 或者 longblob 一样,都是
4G。 - SON数据类型,会自动校验数据是否为JSON格式,如果不是JSON格式数据,则会报错。
- MySQL提供了一组操作JSON数据的内置函数。
- 优化的存储格式,存储在JSON列中的JSON数据被转换成内部的存储格式。其允许快速读取。
- 可以修改特定的键值,(如果之前在MySQL中存储过JSON格式字符串的小伙伴,应该经历过每次修改一个值,都要将整个JSON字符串更新一遍的尴尬。)
JSON 类型的缺点
- JSON列与其他二进制类型列一样是无法创建索引。
|
|
Mysql 配置
-
wait_timeout: 控制连接最大空闲时长
如果你没有修改过MySQL的配置,缺省情况下,wait_timeout的初始值是28800。
wait_timeout 过大有弊端,其体现就是MySQL里大量的SLEEP进程无法及时释放,拖累系统性能,不过也不能把这个指设置的过小,否则你可能会遭遇到“MySQL has gone away”之类的问题,通常来说,我觉得把wait_timeout设置为10是个不错的选择,但某些情况下可能也会出问题,比如说有一个CRON脚本, 其中两次SQL查询的间隔时间大于10秒的话,那么这个设置就有问题了。
1 2 3mysql> set global wait_timeout=30; mysql> show global variables like 'wait_timeout';
窗口函数
MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库中早已支持,也叫分析函数。
语法简介
语法:函数名([参数]) over(partition by [分组字段] order by [排序字段] asc/desc rows/range between 起始位置 and 结束位置)
函数解读:函数分为两个部分,
第一部分是函数名称,开窗函数的数量较少,只有11个窗口函数+聚合函数(所有聚合函数都可以用作开窗函数),根据函数性质,有的要写参数,有的不需要写参数;
第二部分是over语句,over()是必须要写的,里面有三个参数,都是非必须参数,根据需求选写:
1.第一个参数是 partition by + 分组字段,将数据根据此字段分成多份,如果不加partition by参数,那会把整个数据当做一个窗口。
2.第二个参数是 order by + 排序字段,每个窗口的数据要不要进行排序。
3.第三个参数 rows/range between 起始位置 and 结束位置,这个参数仅针对滑动窗口函数有用,是在当前窗口下分出更小的子窗口。其中起始位置和结束位置可写:current row 边界是当前行,unbounded preceding 边界是分区中的第一行,unbounded following 边界是分区中的最后一行,expr preceding 边界是当前行减去expr的值,expr following 边界是当前行加上expr的值。rows是基于行数,range是基于值的大小,到讲解到滑动窗口函数时再详细介绍。
|
|
窗口函数小结
| 类别 | 函数 | 说明 |
|---|---|---|
| 排序 | ROW_NUMBER(连续排名) | 为表中的每一行分配一个序号,可以指定分组(也可以不指定)及排序字段 |
| / | DENSE_RANK(同分同名,不跳级) | 根据排序字段为每个分组中的每一行分配一个序号。 排名值相同时,序号相同,序号中没有间隙(1,1,2,3这种) |
| / | RANK(同分同名,跳级) | 根据排序字段为每个分组中的每一行分配一个序号。 排名值相同时,序号相同,但序号中存在间隙(1,1,3,4这种) |
| / | NTILE | 根据排序字段为每个分组中根据指定字段的排序再分成对应的组 |
| 分布 | PERCENT_RANK | 计算各分组或结果集中行的百分数等级 |
| / | CUME_DIST | 计算某个值在一组有序的数据中累计的分布 |
| 前后 | LEAD | 返回分组中当前行之后的第N行的值。如果不存在对应行,则返回NULL。比如N=1时,第一名对应的值是第二名的,最后一名结果是NULL |
| / | LAG | 返回分组中当前行之前的第N行的值。如果不存在对应行,则返回NULL。比如N=1时,第一名对应的值是是NUL,最后一名结果是倒数第2的值 |
| 首尾中 | FIRST_VALUE | 返回每个分组中第一名对应的字段(或表达式)的值,例如本文中可以是第一名的分数、学号等任意字段的值 |
| / | LAST_VALUE | 返回每个分组中最后一名对应的字段(或表达式)的值,例如本文中可以是最后一名的分数、学号等任意字段的值 |
| / | NTH_VALUE | 返回每个分组中排名第N的对应字段(或表达式)的值,但小于N的行对应的值是NULL |
参考文章
MySQL8.0窗口函数之排名函数(rank、dense_rank)的使用