Mysql 基础知识一
文章目录
常用函数
数据库表的时间戳字段设计,建议使用 int64 类型
|
|
常用命令
|
|
json类型的字段查询
查询JSON中的数据用 column->path的形式,其中对象类型path的表示方式 $.path,数组类型的表示方式 $[index];
|
|
常用案例
|
|
其他
-
数据库目录:
- db.opt //存放数据库配置
- table.frm //存放表结构
- table.MYD //存放表数据
- table.MYI //存放表索引
-
MySQL对InnoDB存储引擎的表进行行级锁定,对MyISAM存储引擎的表进行表级锁定。
-
浮点数计算存在误差问题,如7.22f-7.0f = 0.21999979; 尽量避免做浮点数比较
-
mysql终端连接方式:mysql -uroot -p’password’ –socket=/var/lib/mysql/mysql.sock
-
linux 下 mysql 数据库密码修改
1 2 3 4 5-> mysql -uroot -p -> Enter password: 【输入密码】 mysql> use mysql; mysql> update user set authentication_string=password("test") where user='root'; mysql> flush privileges; -
union 对两个结果集进行并集操作,重复数据只显示一次
Union All,对两个结果集进行并集操作,重复数据全部显示
-
char和varchar使用说明: 根据字符串长度确定,凡是固定长度的字符串或者类似固定长度的字符串一律用char。比如身份证号码,手机号码,银行卡号,MD5,哈希值等这是字符串是固定长度的,毫无疑问用char,还有一类是基本固定长度但是略有出入的,比如中国人的姓名等,一般长度可能是2~5个汉字,这类信息也非常适合用char来存储,只要分配一些略大于通常长度即可。
-
group by
- GROUP BY X -> 意思是将所有具有相同X字段值的记录放到一个分组里。
- GROUP BY X, Y -> 意思是将所有具有相同X字段值和Y字段值的记录放到一个分组里。
-
having: having 子句在聚合后对组记录进行筛选, HAVING 子句总是包含聚集函数
eg: select payment_channel_id, count(1) as total from bi_payment_channel group by payment_channel_id having total>1
-
MySql的like语句中的通配符:百分号、下划线和escape

-
永远不要在MySQL中使用utf8,改用utf8mb4
MySQL的“utf8mb4”是真正的“UTF-8”。“utf8”只支持每个字符最多三个字节,而“utf8mb4”是每个字符最多四个字节。
- mysql5.7 默认排序规则:utf8mb4_general_ci
- mysql8.0 默认排序规则:utf8mb4_0900_ai_ci
utf8mb4_0900_ai_ci字段如何修改为大小写敏感
utf8mb4_0900_ai_ci, 中间的0900,它对应的是Unicode 9.0的规范,ai表示accent insensitivity,也就是“不区分音调”,而ci表示case insensitivity,也就是“不区分大小写”。
mysql8.0默认排序规则是utf8mb4_0900_ai_ci,对大小写不敏感,如果有些字段对大小写敏感的话,需要改下排序规则,如
utf8mb4_0900_as_cs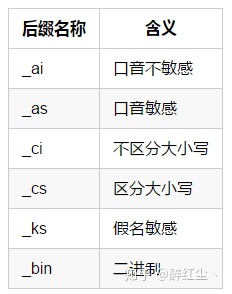
mysql charset 和 collation 有多个级别的设置:服务器级、数据库级、表级、列级和连接级。
1 2 3 4 5 6 7 8 9 10 11# 查看当前数据库各个级别的排序规则 SHOW VARIABLES LIKE 'collation_%'; # 数据库级:修改数据库的默认排序规则 alter database xc character set utf8mb4 collate utf8mb4_0900_as_cs; # 表级:修改表数据的字符集 alter table table_name character set utf8mb4 collate utf8mb4_0900_as_cs; # 列级:修改表内所有字段的字符集 alter table table_name CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_as_cs; -
InnoDB 行锁的触发条件是 where 后面带的字段包含索引。若是没有索引的条件下,就会退化为表锁。然后获取所有行后,Mysql 再过滤符合条件的的行并释放锁。这样就降低了并发度,并且性能开销也会很大。
Mysql 性能
- MySQL 单表数据不要超过500万行:是经验数值,还是黄金铁律?
该理论已过时,mysql 5.7 及以上版本已经可以支持单表几十亿的数据量了,性能还是不错的。
DDL
|
|
数据库设计三范式
-
第一范式1NF
定义:数据库表中的字段都是单一属性的,不可再分。
简单的说,每一个属性都是原子项,不可分割。
1NF是关系模式应具备的最起码的条件,如果数据库设计不能满足第一范式,就不称为关系型数据库。也就是说,只要是关系型数据库,就一定满足第一范式。
-
第二范式2NF
定义:数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖,即符合第二范式。
2NF可以减少插入异常,删除异常和修改异常。
-
第三范式3NF
定义:在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合3NF。
字段类型长度
- TINYTEXT = 255 bytes (2^8 bytes)
- TEXT = 64KB (2^16 bytes)
- MEDIUMTEXT = 16MB (2^24 bytes)
- LONGTEXT = 4GB (2^32 bytes)
不同编码格式一个字符对应不同的字节(中英文符号与字母或汉字都作为字符,占用字节数都一一对应):
- ASCII 码中,一个英文字母(不分大小写)为一个字节,一个中文汉字为两个字节。
- GBK编码中,英文字母一个字节,一个中文汉字两个字节。
- UTF-8 编码中,一个英文字母为一个字节,一个中文为三个字节。
- Unicode 编码中,一个英文为一个字节,一个中文为两个字节。
- UTF-16 编码中,一个英文字母字符或一个汉字字符存储都需要 2 个字节。
- UTF-32 编码中,世界上任何字符的存储都需要 4 个字节。