Mysql 主从复制延时案例
文章目录
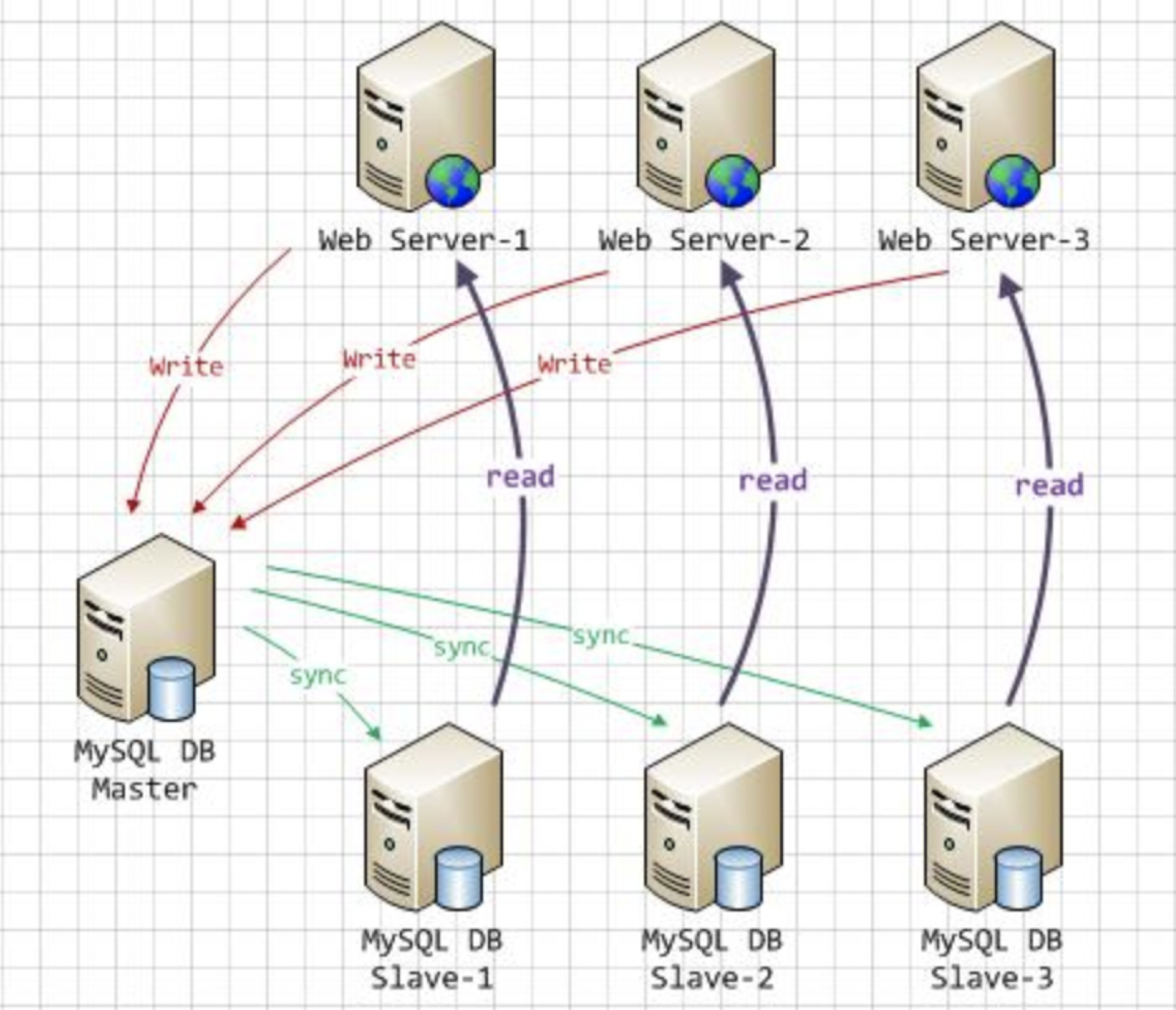
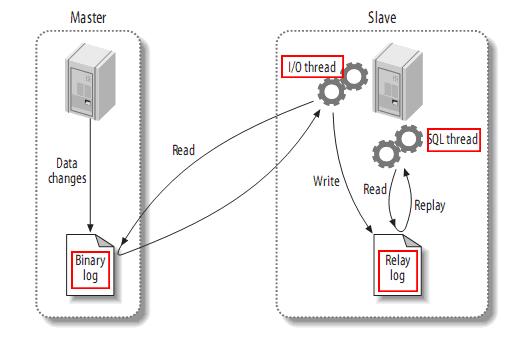
MySQL 主从复制的延时一直是业界困扰已久的问题。延时的出现会降低主从读写分离的价值,不利于数据实时性较高的业务使用 MySQL。
如果主从复制之间出现延时,就会影响主从数据的一致性。
生产环境中延时问题的分析及解决,我们将最常见的主从复制延时案例总结为几类,以下是相关案例的现象描述、原因分析和解决方法汇总。
案例一:主库DML请求频繁
某些用户在业务高峰期间,特别是对于数据库主库有大量的写请求操作,即大量insert、delete、update等并发操作的情况下,会出现主从复制延时问题。
现象描述
我们通过观察主库的写操作的QPS的值,会看到主库的写操作的QPS值突然升高,伴随主从复制延时的上升,可以判断是由于主库DML请求频繁原因造成的。
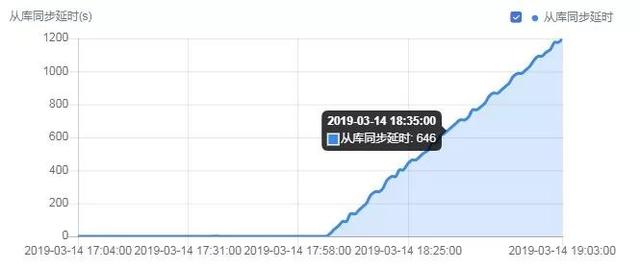
如上图,可以看出,在17:58分左右QPS突增,查看控制台上的写相关QPS,也有相应提升。而QPS突增的时间,对应的延时也在逐步上升,如下图所示。
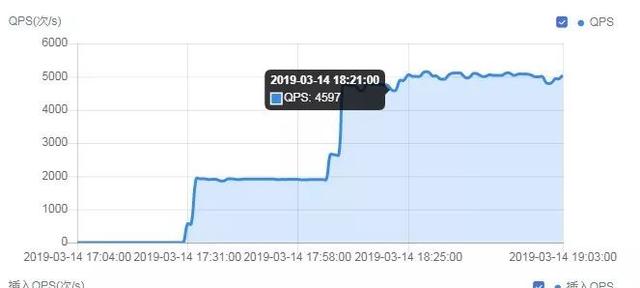
原因分析
经过分析,我们认为这是由于主库大量的写请求操作,在短时间产生了大量的binlog。这些操作需要全部同步到从库,并且执行,因此产生了主从的数据复制延时。
从深层次分析原因,是因为在业务高峰期间的主库写入数据是并发写入的,而从库SQL Thread为单线程回放binlog日志,很容易造成relaylog堆积,产生延时。
解决思路
如果是MySQL 5.7以下的版本,可以做分片(sharding),通过水平扩展(scale out)的方法打散写请求,提升写请求写入binlog的并行度。
如果是MySQL 5.7以上的版本,在MySQL 5.7,使用了基于逻辑时钟(Group Commit)的并行复制。而在MySQL 8.0,使用了基于Write Set的并行复制。这两种方案都能够提升回放binlog的性能,减少延时。
案例二:主库执行大事务
大事务指一个事务的执行,耗时非常长。常见产生大事务的语句有:
使用了大量速度很慢的导入数据语句,比如:INSERT INTO $tb、SELECT * FROM $tb、LOAD DATA INFILE等;
使用了UPDATE、DELETE语句,对于一个很大的表进行全表的UPDATE和DELETE等。
当这个事务在从库执行回放执行操作时,就有可能会产生主从复制延时。
现象描述
我们从SHOW SLAVE STATUS的结果进行分析,会发现 Exec_Master_Log_Pos 字段一直未变,且second_behinds_master持续增加,而 Slave_SQL_Running_State 字段的值为”Reading event from the relay log”;同时,分析主库binlog,看主库当前执行的事务,会发现有一些大事务,这样基本可以判定是执行大事务的原因导致的主从复制延时。
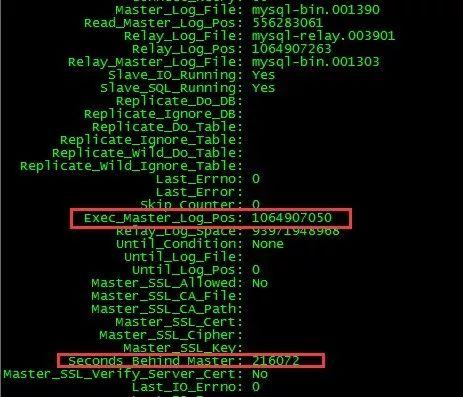
原因分析
当大事务记录入binlog并同步到从库之后,从库执行这个事务的操作耗时也非常长,这段时间,就会产生主从复制延时。
举个例子,假如主库花费200s更新了一张大表,在主从库配置相近的情况下,从库也需要花几乎同样的时间更新这张大表,此时从库延时开始堆积,后续的events无法更新。
解决思路
对于这种情况引起的主从复制延时,我们的改进方法是:拆分大事务语句到若干小事务中,这样能够进行及时提交,减小主从复制延时。
案例三:主库对大表执行DDL语句
DDL全称为 Data Definition Language ,指一些对表结构进行修改操作的语句,比如,对表加一个字段或者加一个索引等等。当DDL对主库大表执行DDL语句的情况下,可能会产生主从复制延时。
现象描述
从现象上,如果从库执行SHOW SLAVE STATUS的输出中,检查Exec_Master_Log_Pos一直未动,在排除主库执行大事务的情况下,那么就有可能是在执行大表的 DDL。这一点结合分析主库binlog,看主库当前执行的事务就可以进行确认。
DDL语句的执行情况,可以进一步细分现象来更好地判断:
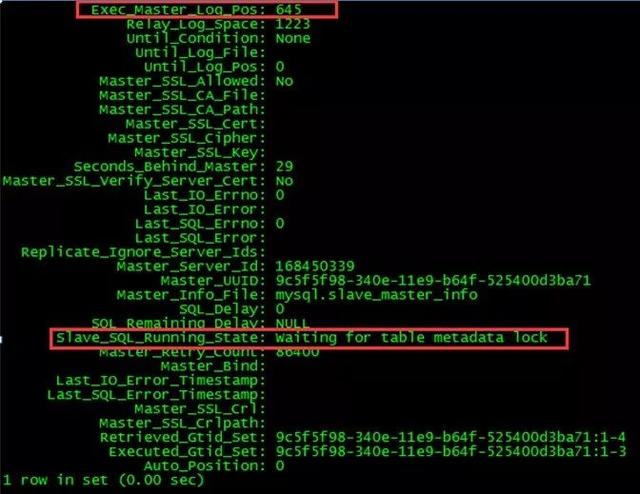
1.DDL未开始,被阻塞,这时SHOW SLAVE STATUS的结果能检查到Slave_SQL_Running_State为waiting for table metadata lock,且Exec_Master_Log_Pos不变;
2.DDL正在执行,SQL Thread单线程应用导致延时增加。这种情况下观察SHOW SLAVE STATU的结果能发现Slave_SQL_Running_State为altering table,而Exec_Master_Log_Pos不变。
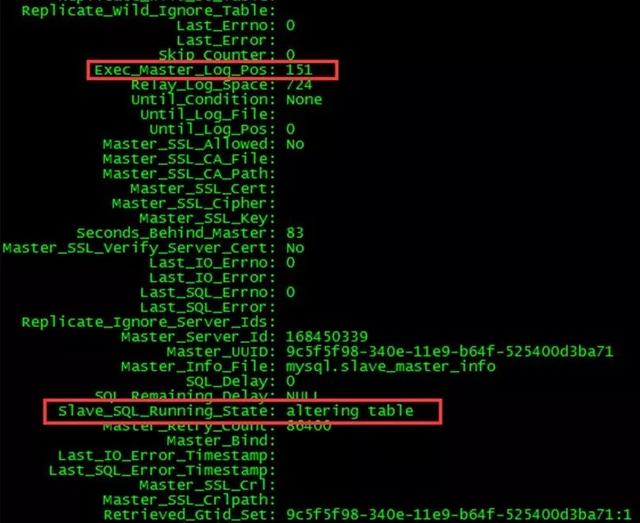
如果有上述的现象,那么很有可能主库对大表执行DDL语句,同步到从库并在从库回放时,就产生了主从复制延时。
原因分析
DDL导致的主从复制延时的原因和大事务类似,也是因为从库执行DDL的binlog较慢而产生了主从复制延时。
解决思路
遇到这种情况,我们主要通过SHOW PROCESSLIST或对information_schema.innodb_trx做查询,来找到阻塞DDL语句,并KILL掉相关查询,让DDL正常在从库执行。
DDL本身造成的延时难以避免,建议考虑:
避免业务高峰,尽量安排在业务低峰期执行 ; set sql_log_bin=0后,分别在主从库上手动执行DDL(此操作对于某些DDL操作会造成数据不一致,请务必严格测试),这一条如果用户使用云数据库UDB,可以联系UCloud UDB运维团队进行协助操作。
案例四:主库与从库配置不一致
如果主库和从库使用了不同的计算资源和存储资源,或者使用了不同的内核调教参数,可能会造成主从不一致。
现象描述
我们会详细比对主库和从库的性能监控数据,如果发现监控数据差异巨大,结合查看主从的各个配置情况,即可作出明确判断。
原因分析
各种硬件或者资源的配置差异都有可能导致主从的性能差异,从而导致主从复制延时发生:
硬件上:比如,主库实例服务器使用SSD磁盘,而从库实例服务器使用普通SAS盘,那么主库产生的写入操作在从库上不能马上消化掉,就产生了主从复制延时;
配置上:比如,RAID卡写策略不一致、OS内核参数设置不一致、MySQL落盘策略不一致等,都是可能的原因。
解决思路
考虑尽量统一DB机器的配置(包括硬件及选项参数)。甚至对于某些OLAP业务,从库实例硬件配置需要略高于主库。
案例五:表缺乏主键或合适索引
如果数据库的表缺少主键或者合适索引,在主从复制的binlog_format设置为’row’的情况下,可能会产生主从复制延时。
现象描述
我们进行数据库检查时,会发现:
观察SHOW SLAVE STATUS的输出,发现Slave_SQL_Running_State为Reading event from the relay log;
SHOW OPEN TABLES WHERE in_use=1的表一直存在;
观察SHOW SLAVE STATUS的Exec_Master_Log_Pos字段不变;
mysqld进程的CPU接近100%(无读业务时),IO压力不大。
这些现象出现的情况下,可以认为很可能有表缺乏主键或唯一索引。
原因分析
在主从复制的binlog_format设置为’row’的情况下,比如有这样的一个场景,主库更新一张500万表中的20万行数据。binlog在row格式下,记录到binlog的为20万次update操作,也就是每次操作更新1条记录。如果这条语句恰好有不好的执行计划,如发生全表扫描,那么每一条update语句需要全表扫描。此时SQL Thread重放将特别慢,造成严重的主从复制延时。
解决思路
这种情况下,我们会去检查表结构,保证每个表都有显式自增主键,并协助用户建立合适索引。
案例六:从库自身压力过大
有时候,从库性能压力很大的情况下,跟不上主库的更新速度,就产生了主从复制延时。
现象描述
观察数据库实例时,会发现CPU负载过高,IO利用率过高等现象,这些导致SQL Thread应用过慢。这样就可以判断是因为从库自身压力过大引起主从复制延时。
原因分析
部分UCloud用户对于数据库的主从会使用读写分离模式,读请求大部分在从库上执行。在业务有大量读请求的场景下,从库会产生比主库大得多的性能压力。有的用户甚至会在从库运行十分耗费计算资源的OLAP业务,这也对从库造成了更高的性能挑战,这些都会造成主从复制的延时。
解决思路
这种情况下,我们会建议用户建立更多从库,打散读请求,降低现有从库实例的压力。对于OLAP业务来说,可以专门建立一个从库来做OLAP业务,并对这个从库,允许适当的主从复制延时。
案例七:MySQL 主从同步延时问题
以前线上确实处理过因为主从同步延时问题而导致的线上的 bug,属于小型的生产事故。
是这个么场景。有个同学是这样写代码逻辑的。先插入一条数据,再把它查出来,然后更新这条数据。在生产环境高峰期,写并发达到了 2000/s,这个时候,主从复制延时大概是在小几十毫秒。线上会发现,每天总有那么一些数据,我们期望更新一些重要的数据状态,但在高峰期时候却没更新。用户跟客服反馈,而客服就会反馈给我们。
我们通过 MySQL 命令:
|
|
查看 Seconds_Behind_Master,可以看到从库复制主库的数据落后了几 ms。
一般来说,如果主从延迟较为严重,有以下解决方案:
- 分库,将一个主库拆分为多个主库,每个主库的写并发就减少了几倍,此时主从延迟可以忽略不计。
- 打开 MySQL 支持的并行复制,多个库并行复制。如果说某个库的写入并发就是特别高,单库写并发达到了 2000/s,并行复制还是没意义。
- 重写代码,写代码的同学,要慎重,插入数据时立马查询可能查不到。
- 如果确实是存在必须先插入,立马要求就查询到,然后立马就要反过来执行一些操作,对这个查询设置直连主库。不推荐这种方法,你要是这么搞,读写分离的意义就丧失了。
阿里数据库:有 2 个方案可以让读请求路由到主库:『发红包场景可能需要用到,为了避免主从延迟问题,让红包查询 sql 只读主库』
- 包含了事务的所有请求只会路由到主库(包括事务读)。
- 所有被分配读权重的只读实例处于不可用状态或其延迟时间超过了您所设置的延迟阈值,系统将其判定为不可用状态
总结
在使用MySQL的主从复制模式进行数据复制时,主从复制延时是一个需要考量的关键因素。它会影响数据的一致性,进而影响数据库高可用的容灾切换。
在遇到数据库之间出现主从复制延时的情况下,我们团队基于过往经验,归纳出以下方法与流程来协助排查问题:
通过 SHOW SLAVE STATUS 与 SHOW PROCESSLIST 查看现在从库的情况。(顺便也可排除在从库备份时的类似原因);
若Exec_Master_Log_Pos不变,考虑大事务、DDL、无主键,检查主库对应的binlog及position即可;
若Exec_Master_Log_Pos变化,延时逐步增加,考虑从库机器负载,如IO、CPU等,并考虑主库写操作与从库自身压力是否过大。
转载声明
作者:资深专家丁顺&张苏宁
链接:http://blog.ucloud.cn/archives/4132
来源:UCloud技术
著作权归作者所有,任何形式的转载都请联系作者