Canal
文章目录
canal 简介
canal 是阿里开发的一款基于数据库增量日志解析,提供增量数据订阅与消费的框架,可以很方便地同步数据库的增量数据到其他的存储应用。
整个框架纯JAVA开发,目前仅支持 Mysql 和 MariaDB(和mysql类似)。
原理
把自己伪装成 MySQL slave,模拟 MySQL slave 的交互协议向 MySQL Mater 发送 dump 协议,MySQL master 收到 canal 发送过来的 dump 请求,开始推送 binary log 给 canal,然后 canal 解析 binary log,再发送到存储目的地,比如 MySQL,Kafka,Elastic Search 等等。
那什么是数据库增量日志?
MySQL 的日志种类是比较多的,主要包含:错误日志、查询日志、慢查询日志、事务日志、二进制日志。而MySQL数据库所发生的数据变更(DML(data manipulation language)数据操纵语言,也就是我们熟悉的增删改),都会以二进制日志(binary log)形式存储。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份『数据库可授权 某个账号只读某几张表,所以可实现实时备份部分表的功能』
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
基于Canal+Kafka实现缓存实时更新
前言
相信对于大部分同学来说,缓存应该是平时开发中会经常接触的东西了。常规的逻辑一般是「查询」->「检查是否有缓存」如果有,就直接返回;如果没有,则从 DB 中读取数据。后续对数据进行过更新之后,再删除 / 更新缓存。
所以从流程上来看读缓存很容易,难的是保证缓存数据的有效性,大多数的做法是在业务代码中嵌入更新缓存的逻辑。比如在修改某篇文章成功之后,删除原有的 key。
正常情况下这种方式没有问题,但有时我们的系统中不止一个地方会修改这些数据,那么我们就不得不在每处业务代码中植入更新缓存的逻辑,随着时间的推移,我们的代码变得越来越臃肿,难以维护。
那么有没有什么方法可以让我们可以不用花费太多精力来关注业务之外的事情呢?当然有,这就是我们今天要介绍的工具 Canal。
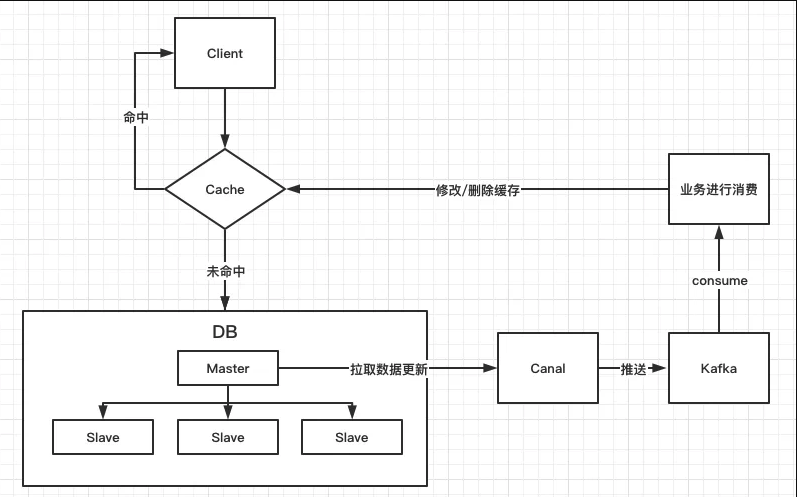
工作流程
说明:大体流程就是 canal 充当一个 mysql 的从服务器,从 master 拉取 binlog 变化,将更新内容推送至 kafka 中,然后客户端启动消费者订阅主题,根据数据变化执行对应的业务逻辑。
类似产品
阿里云数据传输服务DTS
数据传输服务DTS(Data Transmission Service)支持RDBMS、NoSQL、OLAP等数据源间的数据交互,集数据迁移/订阅/同步于一体,助您构建安全、可扩展、高可用的数据架构。
相对于第三方数据流工具,数据传输服务 DTS 提供更丰富多样、高性能、高安全可靠的传输链路,同时它提供了诸多便利功能,极大得方便了传输链路的创建及管理。