行存储模式和列存储模式
文章目录
行存储和列存储,是数据库底层组织数据的方式。(和文档型、K-V 型,时序型等概念不在一个层次)
行存储
行存储系统以行的方式来组织数据。
|
|
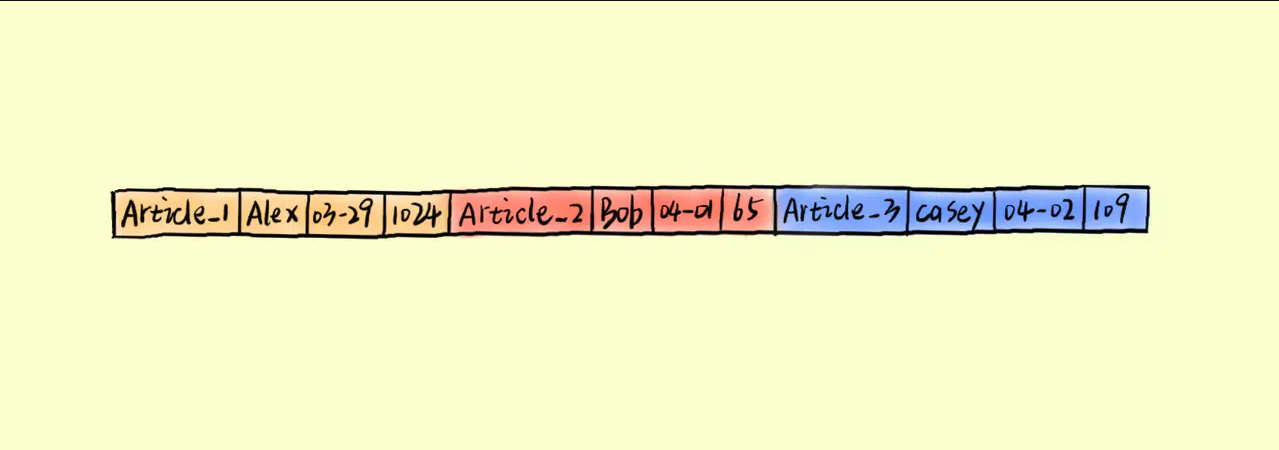
行存储将会以上图方式将数据存储在磁盘上。行存储利于数据一行一行的写入,写入一条数据记录时,只需要将数据追加到已有数据记录后面即可。
行模式存储适合 OLTP(Online Transaction Processing)系统。因为数据基于行存储,所以数据的写入会更快。对按记录查询数据也更简单。
大部分同学会问,我们的做的系统不就是在为了这个吗?所以我为什么还需要列式存储,而列式存储又是什么?
让我们想象一种场景,现在不是想查询 Bob 的博客,我想统计 Bob 发表的博客数,或是整个系统今天的博客点赞数。如果是行存储系统,数据库将怎样操作?
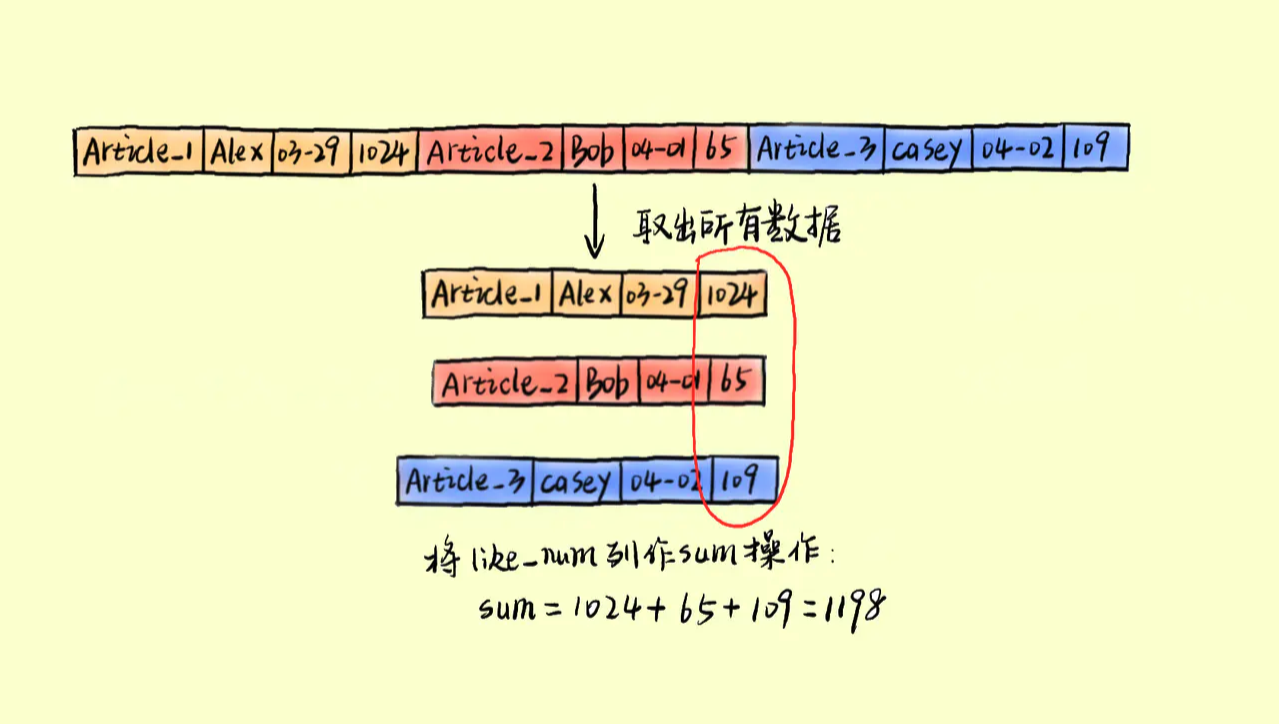
如图,想统计所有点赞数,首先需要将所有行数据读入内存,然后对 like_num 列做 sum 操作,从而得到结果。我们假设磁盘一次可以读取图中 3 个方框的数据(实际需要按 byte 来读取),那么这个聚合计算需要 N(N=数据量)次磁盘访问。
这种经常需要通过大量数据集来聚合统计数据的需求其实是 OLAP 系统的常见行为。基于这个需求我们也可以明白为什么这几年列式存储开始流行。因为数据,大数据,数据分析,也就是 OLAP(Online Analytical Processing)在线分析系统的需求增多了,数据写入的事务和按记录查询数据都不是它的关注点,它关注的是数据过滤,统计。
列存储
同样是上面的示例数据,我们来看列式存储是怎样组织数据的。
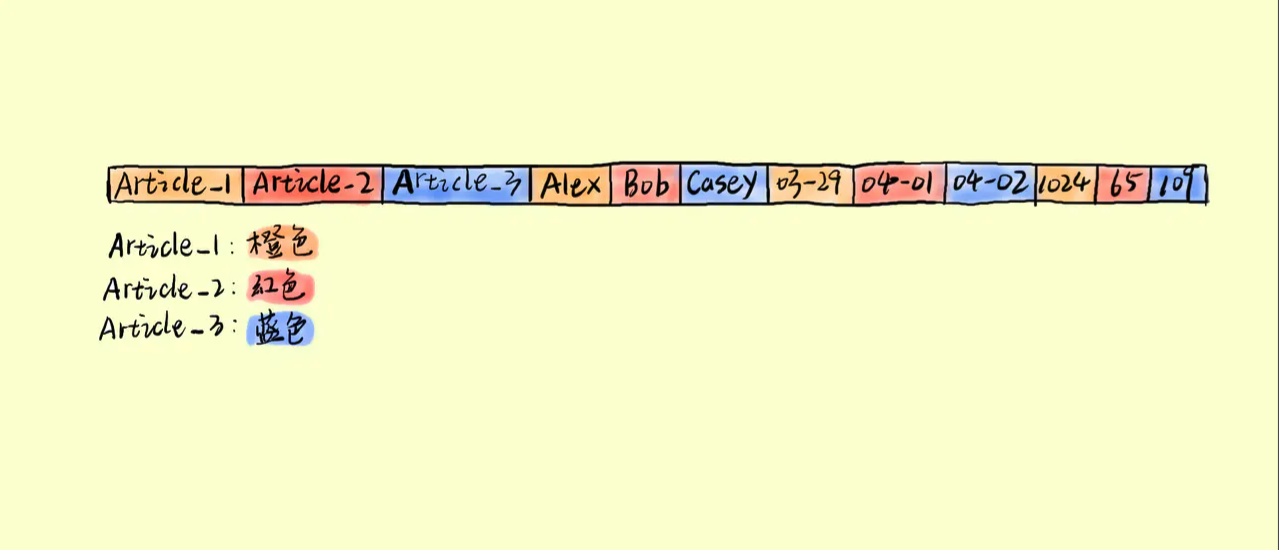
如上图所示,列式存储将每一列的数据组织在一起。列存储利于对于列的操作,如上面我们说到的统计所有 like_num 之和。其过程将如下:
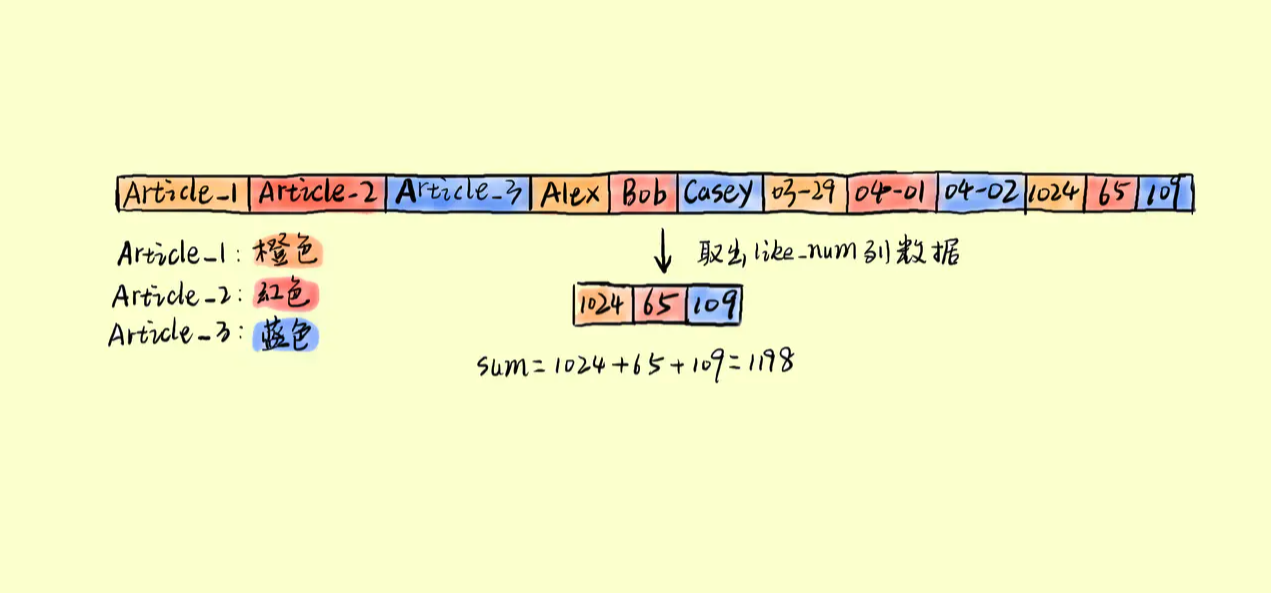
依然假设磁盘一次可以读取 3 个方框的数据(实际按 byte 读取)。可以看出按列存储组织数据的方式,只需要 1 次磁盘操作就可以完成。
在程序的世界里,我们学会了,任何的选择和倾向都是有代价的。空间换时间,时间换空间,一致性可用性相互平衡等。选择列式存储必然也有不利的一面。首先就表现在数据写入上。
列存储缺点
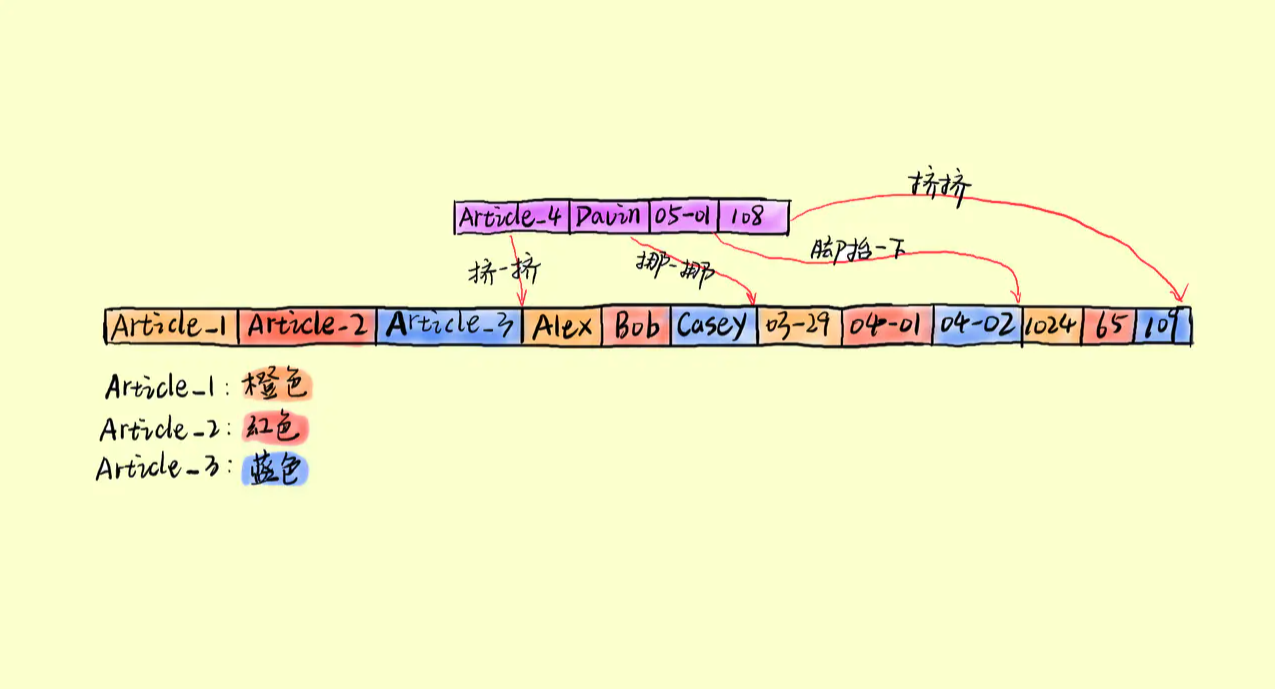
当一条新数据到来,需要将每一列存储到对应的位置。这样就需要多次写磁盘操作。(当然真实的数据库不会出现图中”挤一挤“、”挪一挪“的情况,数据库会将不同列数据组织在不同的地方;对于多次写操作的问题,大部分存储系统会通过缓冲来降低这种情况带来的不足)
列模存储优势
- 自动索引
因为基于列存储,所以每一列本身就相当于索引。所以在做一些需要索引的操作时,就不需要额外的数据结构来为此列创建合适的索引。
- 利于数据压缩
利于压缩有两个原因。一来你会发现大部分列数据基数其实是重复的,拿上面的数据来说,因为同一个 author 会发表多篇博客,所以 author 列出现的所有值的基数肯定是小于博客数量的,因此在 author 列的存储上其实是不需要存储博客数量这么大的数据量的;二来相同的列数据类型一致,这样利于数据结构填充的优化和压缩,而且对于数字列这种数据类型可以采取更多有利的算法去压缩存储。
总结
读写均慢,但利于大数据及的数据聚合操作。
对比
| Row-Store | Column-Store |
|---|---|
| 因为按一行一行写和读取数据,因此读取数据时往往需要读取那些不必要的列 | 可以只读取必要的列 |
| 易于按记录读写数据 | 对一个一个记录的数据写入和读取都较慢 |
| 适合 OLTP 系统 | 适合 OLAP 系统 |
| 不利于大数据集的聚合统计操作 | 利于大数据集的数据聚合操作 |
| 不利于压缩数据 | 利于压缩数据 |
转载声明
作者:码哥字节
链接:https://juejin.cn/post/6844904118872440840
来源:掘金
著作权归作者所有,任何形式的转载都请联系作者