ElasticStack
文章目录
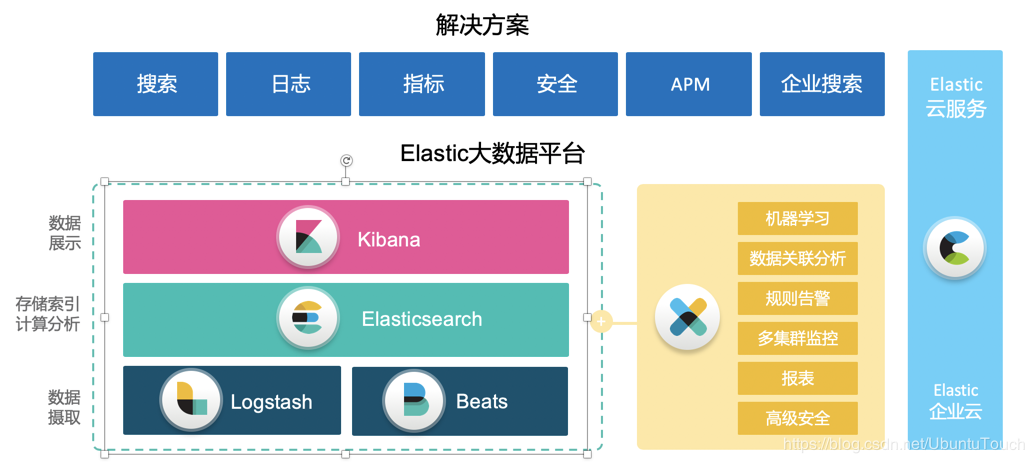
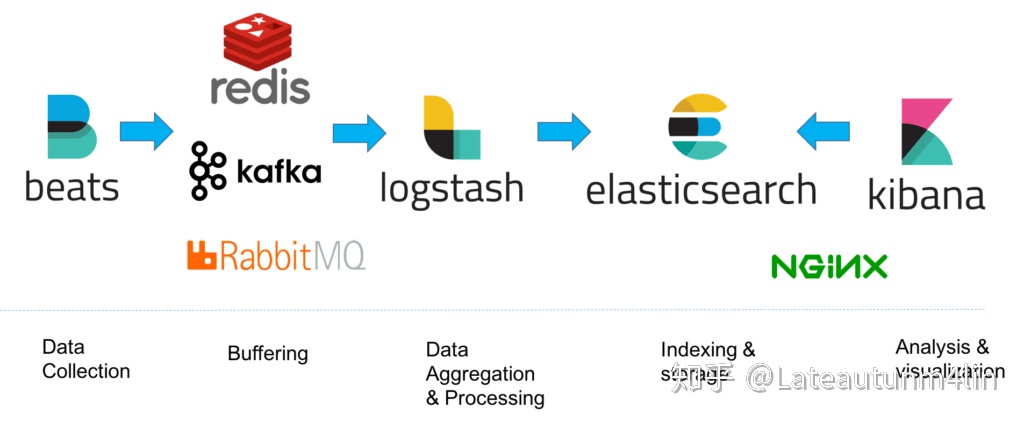
Elastic Stack
“ELK”是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一个搜索和分析引擎,可扩展的高速体验,涵盖搜索、分析和存储。
Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。
Kibana 对 Elasticsearch 数据进行可视化,可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
而 Elastic Stack 是 ELK Stack 的更新换代产品。
Elasticsearch
一、Elasticsearch是什么
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
Elasticsearch 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node),一组节点构成一个集群(cluster)。
二、Elasticsearch中涉及到的重要概念
-
接近实时(NRT)
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒)。
-
集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
-
节点(node)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
-
索引(index, es6 类似于关系型数据库中 Database 的概念,es7 类似于 Table 的概念)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
-
类型(type,类似于关系型数据库中 Table 的概念,es7 之后移除)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
-
文档(document,类似于关系型数据库中 Record 的概念)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,只要你想,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
实际上一个文档除了用户定义的数据外,还包括_index、_type和_id字段。
-
分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,主要有两方面的原因:
在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
-
es6 和 es7 的区别
- es6: index: database, type: table, document: record
- es7: index: table, document: record『type 被移除』
三、分词
搜索引擎的核心是倒排索引,而倒排索引的基础就是分词。所谓分词可以简单理解为将一个完整的句子切割为一个个单词的过程。在 es 中单词对应英文为 term。
ES 的倒排索引即是根据分词后的单词创建,即 我、爱、北京、天安门这4个单词。这也意味着你在搜索的时候也只能搜索这4个单词才能命中该文档。
实际上 ES 的分词不仅仅发生在文档创建的时候,也发生在搜索的时候,如下:
-
读时分词发生在用户查询时,ES 会即时地对用户输入的关键词进行分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
-
写时分词发生在文档写入时,ES 会对文档进行分词后,将结果存入倒排索引,该部分最终会以文件的形式存储于磁盘上,不会因查询结束或者 ES 重启而丢失。『通常采用此方案』
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19// 写时分词示例:title 字段采用英文分词器进行分词 PUT /zsm-test { "settings": { "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "english" }, "category": { "type": "text" } } } }
ES 中处理分词的部分被称作『分词器』,英文是Analyzer,它决定了分词的规则。ES 自带了很多默认的分词器,比如Standard、 Keyword、Whitespace等等,默认是 Standard。当我们在读时或者写时分词时可以指定要使用的分词器。
四、常用的分词器
-
standard
- 默认分词器
- 按词分类『中文会拆分成一个个字处理』
- 小写处理
-
whitespace
- 按空格切分
-
Language Analyzer
支持语言:english, arabic, armenian, basque, bengali, bulgarian, catalan, czech, dutch, finnish, french, galician, german, hindi, hungarian, indonesian, irish, italian, latvian, lithuanian, norwegian, portuguese, romanian, russian, sorani, spanish, swedish, turkish.
-
中文分词器「非默认分词器,需自行安装」
1 2# use elasticsearch-plugin to install: replace 7.7.0 to your own elasticsearch version elasticsearch-7.7.0/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.0/elasticsearch-analysis-ik-7.7.0.zip-
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
-
ik_smart:会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16// 我们可以在索引时使用 ik_max_word,在搜索时使用 ik_smart。 { "settings":{ "number_of_shards": 1, "number_of_replicas": 0 }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, } } } -
五、常用的 RESTful API 介绍
我们可以在请求中添加 help 参数来查看每个操作返回结果字段的意义,如 curl -X GET “localhost:9200/_cat/indices?help”。
|
|
|
|
|
|
kibana
- 最常用的功能:菜单 -> Dev Tools -> Console,用于调试 es api 接口
Install on macOS with darwin
可以指定安装版本
|
|
Install on macOS with brew
|
|
|
|
相关配置
|
|
|
|
版本问题
Kibana 的版本需要和 Elasticsearch 的版本一致。这是官方支持的配置。
运行不同主版本号的 Kibana 和 Elasticsearch 是不支持的(例如 Kibana 5.x 和 Elasticsearch 2.x),若主版本号相同,运行 Kibana 子版本号比 Elasticsearch 子版本号新的版本也是不支持的(例如 Kibana 5.1 和 Elasticsearch 5.0)。
运行一个 Elasticsearch 子版本号大于 Kibana 的版本基本不会有问题,这种情况一般是便于先将 Elasticsearch 升级(例如 Kibana 5.0 和 Elasticsearch 5.1)。在这种配置下,Kibana 启动日志中会出现一个警告,所以一般只是使用于 Kibana 即将要升级到和 Elasticsearch 相同版本的场景。
运行不同的 Kibana 和 Elasticsearch 补丁版本一般是支持的(例如:Kibana 5.0.0 和 Elasticsearch 5.0.1),尽管我们鼓励用户去运行最新的补丁更新版本。
Laravel Scout
一、Laravel Scout 配置
-
配置模型索引
每个 Eloquent 模型都是通过给定的搜索“索引”进行同步,该索引包含了所有可搜索的模型记录,换句话说,你可以将索引看作是一个 MySQL 数据表。
默认情况下,每个模型都会被持久化到与模型对应表名(通常是模型名称的复数形式)相匹配的索引中,
不过,你可以通过重写模型中的 searchableAs 方法来覆盖这一默认设置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21<?php namespace App\Models; use Laravel\Scout\Searchable; use Illuminate\Database\Eloquent\Model; class Post extends Model { use Searchable; /** * 获取模型的索引名称. * * @return string */ public function searchableAs() { return 'posts_index'; } } -
配置搜索数据
默认情况下,模型以完整的 toArray 格式持久化到搜索索引,如果你想要自定义被持久化到搜索索引的数据,可以重写模型上的 toSearchableArray 方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25<?php namespace App\Models; use Laravel\Scout\Searchable; use Illuminate\Database\Eloquent\Model; class Post extends Model { use Searchable; /** * 获取模型的索引数据数组,类似 mysql 需要搜索的表字段名 * * @return array */ public function toSearchableArray() { $array = $this->toArray(); # 自定义数组... return $array; } } -
配置模型 ID
默认情况下,Scout 会使用模型的主键作为唯一ID将其存储到搜索索引中。如果你需要自定义这个行为,可以在模型类中重写 getScoutKey 方法『默认使用 id 作为 key』:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21<?php namespace App\Models; use Laravel\Scout\Searchable; use Illuminate\Database\Eloquent\Model; class User extends Model { use Searchable; /** * Get the value used to index the model. * * @return mixed */ public function getScoutKey() { return $this->email; # 返回 mysql 字段名 } }
二、Laravel 初始化 es 和创建索引
php artisan make:command InitEs
|
|
三、Laravel Scout 索引批量导入/删除
即 mysql 等数据库的已有数据导入 ES
-
如果将 Scout 安装到了已存在的项目,可能该项目之前已经有了可以导入搜索驱动的数据库记录,Scout 提供了 Artisan 命令 import 用于导入所有已存在的数据到搜索索引:
php artisan scout:import “App\Models\Post”
-
flush 方法可用于从搜索索引中移除所有模型记录:
php artisan scout:flush “App\Models\Post”
四、使用
|
|